The CLARIN Knowledge Centre for South Slavic languages (CLASSLA) offers expertise on language resources and technologies for South Slavic languages. Its basic activities are (1) giving researchers, students, citizen scientists and other interested parties information on the available resources and technologies via its documentation, (2) supporting them in producing, modifying or publishing resources and technologies via its helpdesk and (3) organizing training activities. Read more about CLASSLA’s activities and its mission in a Tour de CLARIN article, published here.
CLASSLA can be contacted via helpdesk.classla@clarin.si. The helpdesk offers additional clarifications regarding the CLASSLA documentation (detailed below) and support in using, modifying, producing, or publishing resources and technologies for South Slavic languages.
The Knowledge Centre currently offers frequently asked questions (FAQ) documentation for the following languages: Slovene, Croatian, Serbian, Bulgarian, and Macedonian. It also offers documentation on how to use CLARIN.SI web services which currently cover Slovene, Croatian and Serbian.
The most relevant announcements, discussed in our mailing list, are made available below. You can subscribe to the mailing list here to be informed of new resources, technologies, events and projects for South Slavic languages.
Stay updated on the latest activities of the CLASSLA Knowledge Centre and the CLARIN.SI infrastructure by following:
- CLARIN.SI on X and LinkedIn
- the Discord group “Slovenska skupnost za jezikovne vire in tehnologije”
You can access the new resources and technologies developed by researchers from CLASSLA and CLARIN.SI in the following repositories:
CLASSLA is operated by CLARIN.SI, the Institute of Croatian Language, and CLADA-BG.
The CLASSLA K-Centre is part of the CLARIN ERIC K-Centres network, offering expertise in various languages, language technologies, resources, and services. Learn more about other K-Centres that might be relevant for you in the CLARIN K-Centre Catalogue.
![]()
CLASSLA Blog Posts
- Exploring Internet Language: A Step-By-Step Guide To Corpus Analysis With CLASSLA-Web (May 28, 2026)
- Comparable CLASSLA web corpora of South Slavic languages (December 5, 2023; 3-minutes read)
- CLASSLA-web: Bigger and Better Web Corpora for Croatian, Serbian and Slovenian on CLARIN.SI Concordancers (June 22, 2023; 10-minutes read)
Recent Announcements
February 12, 2026 – CLASSLA LLM Evaluation Dashboard for South Slavic Languages
Are you wondering which large language model performs the best on South Slavic languages and dialects? Or what is the performance of models for sentiment, topic, genre classification and commonsense reasoning tasks, especially compared to previous state-of-the-art models that have been especially trained on these tasks?
At CLASSLA and CLARIN.SI, we have now set up an interactive dashboard that allows you to search through the results of our evaluation of large language models on various tasks. The models are evaluated on carefully manually-annotated datasets most of which we developed in various previous projects. You are warmly invited to visit the dashboard here: https://www.clarin.si/classla-llm-dashboard/
For more details:
– Read the paper on the benchmarking experiments and results “State of the Art in Text Classification for South Slavic Languages: Fine-Tuning or Prompting?” (Taja Kuzman Pungeršek, Peter Rupnik, Ivan Porupski, Vuk Dinić, Nikola Ljubešić, 2025)
– Consult the code for the experiments published on GitHub
December 29, 2025 – CLASSLA Annual Recap: 2025 in Review
As we wrap up another eventful year, we would like to share an overview of the key developments and activities at the CLASSLA Knowledge Centre for South Slavic Languages during 2025.
CLASSLA-web corpora for South Slavic languages
We are excited to announce that we have released the second version of the CLASSLA-web corpora, comprising texts that were collected from the web in 2024. You can now query the new corpora on the CLARIN.SI concordancer (Bosnian, Bulgarian, Croatian, Macedonian, Montenegrin, Serbian, and Slovenian corpora), download them from the CLARIN.SI repository or find more information about both 1.0 and 2.0 versions of CLASSLA-web corpora on a new website: https://clarinsi.github.io/classla-web/
Although collected from the same national domains as version 1.0 from 2021 and 2022, the new release is substantially larger and contains mostly new material: around 50% more texts and words, totalling 38 million texts and 17 billion words across seven South Slavic languages. The corpora are linguistically annotated with an improved CLASSLA-Stanza tool (available as a service here) and a multilingual genre classifier X-GENRE. In addition, version 2.0 now also includes topic labels based on our multilingual news topic classifier. The corpora are available on the CLARIN.SI repository in JSONL and linguistically-annotated VERT formats.
CLASSLA-Express workshop series
Our CLASSLA-Express workshop programme expanded both in content and geography. This year, seven workshops were held across four countries – Austria, Bulgaria, Croatia, and Slovenia – led primarily by Ivana Filipović Petrović and Jelena Parizoska, with contributions from Petya Osenova and local organizers. In addition to demonstrating the use of CLARIN.SI concordancers and the CLASSLA-web corpora, the workshops introduced new topics with a strong focus on applying modern AI methods in linguistic research. We are delighted by the continued interest and encourage you to explore the detailed workshop reports available on our website. You are warmly invited to stay tuned: CLASSLA-Express 3.0, with a new focus on spoken corpora, is already on the horizon.
Benchmarking large language models for South Slavic languages and dialects
Evaluation of large language models (LLMs) continued to be one of our key activities. This year, we participated in development of multiple South Slavic benchmarks for LLM evaluation, including the Global-PIQA test set, a multilingual commonsense reasoning benchmark developed by 335 co-authors and covering 116 languages and dialects, including standard South Slavic languages, as well as Torlak, Chakavian, and the Slovenian Cerkno dialects.
In parallel, we launched an interactive platform presenting evaluation results for South Slavic languages and dialects across six tasks: two commonsense reasoning benchmark families (COPA and PIQA), sentiment classification, news topic classification, and automatic genre identification. The platform enables researchers and developers to compare large language model performance, identify strengths and weaknesses, and follow developments over time. To support further experimentation and application, we provide an accompanying paper with an overview of current model performance as well as open-source code for running evaluations and adapting LLMs to new tasks. We are excited to continue our benchmarking activities as part of the LLM4DH and LLMs4EU projects, which will extend over the next few years.
Speech corpora and technologies
Our efforts in speech resources advanced significantly this year, with a major focus on expanding and enriching parliamentary speech corpora. A key achievement was the release of ParlaSpeech 3.0, a multilingual collection covering Croatian, Serbian, Czech, and Polish parliamentary proceedings. In the new release, ParlaSpeech has been extended with five annotation layers: linguistic annotation, sentiment labels, filled-pause detection, precise word-level alignments, and primary stress information. These enrichment layers have been added automatically with cutting-edge models for processing speech and text, most of which can be found on the CLASSLA Hugging Face page. The enrichments enable advanced studies of prosody, disfluency patterns, and multimodal aspects of parliamentary speech. In addition to the CLARIN.SI repository, the corpora are now accessible through the CLARIN.SI concordancers (Croatian, Serbian, Czech and Polish), accompanied by a tutorial on how to query them.
Supporting SSH researchers in working with large language models
As part of the newly established LLMs4SSH CLARIN Knowledge Centre, we contributed expertise to help researchers in the social sciences and humanities navigate the rapidly evolving landscape of large language models. Our contributions included an overview of Slovenian activities, technologies, and datasets related to LLM development; a proposal for a new taxonomy for LLM evaluation datasets; and a concept for a European database offering a clear map of available resources by language and evaluation task.
Models and datasets on Hugging Face
This year, numerous new models and datasets were released to the CLASSLA Hugging Face page, including the first openly-available multilingual IPTC news topic classifier, which has already surpassed 600,000 downloads. We are thrilled to see such strong uptake and will continue expanding the collection of openly accessible tools and corpora for South Slavic languages and beyond.
Looking ahead
As we reflect on this year’s achievements, we extend our sincere thanks to all team members and collaborators who have contributed to our activities, and to the users who uptake on our resources. Your engagement and feedback drive our continued commitment to supporting linguistic research and technology development for South Slavic languages.
We look forward to another productive year filled with exciting advances and new collaborations. Wishing you a successful and inspiring year ahead!
October 17, 2025 – Parliamentary ParlaCAP Dataset and CAP Topic Classifier
CLARIN.SI is pleased to announce the release of the ParlaCAP dataset: an extension of the ParlaMint 5.0 collection enriched with sentiment and topic annotations, as well as extended metadata on parties and democracies. The dataset contains around 8 million speeches from 28 European parliaments, and is provided in a tabular format, enhancing the usability of the ParlaMint corpora for social and political science research. As part of the OSCARS ParlaCAP project, the dataset was published through the Croatian CESSDA node CROSSDA, promoting thereby collaboration between infrastructures. We also released the multilingual topic classifier using the CAP (Comparative Agendas Project) labels, and tutorials for analysing ParlaCAP data in Python. More information is available here.
June 2, 2025 – An overview of LLM activities in Slovenia (LLMs4SSH Knowledge Centre)
At CLARIN.SI, we have launched a new webpage highlighting current research activities related to large language models (LLMs) in Slovenia, created in the context of our membership in the CLARIN ERIC LLMs4SSH Knowledge Centre.
Explore the page here: https://www.clarin.si/info/k-centres/llms4ssh-clarin-k-centre-for-large-language-models-in-ssh/
The page is also available in Slovenian language: https://www.clarin.si/info/k-centri/llms4ssh-sredisce-znanja-za-velike-jezikovne-modele-za-druzboslovje-in-humanistiko/
The site brings together essential information on:
- key projects focusing on LLMs in which Slovenia is participating,
- existing benchmarks for LLMs in Slovenian,
- benchmarks and datasets for LLM evaluation in South Slavic and other languages provided by the CLASSLA Knowledge Centre,
- the openly-available large language models, speech technologies, and other natural-language processing (NLP) technologies for Slovenian – see the overview here.
We invite researchers, developers, and anyone interested in LLMs for Slovenian and other languages to explore the webpage and make use of these resources.
If there’s important information or a resource we’ve missed, we would be happy to include it – just get in touch via our helpdesk (helpdesk.classla@clarin.si).
May 15, 2025 – CLASSLA-Express 2.0 in Zagreb: Corpora vs. Large Language Models
We invite you to attend the workshop “CLASSLA-Express 2.0: Corpora vs. Large Language Models”, taking place as a pre-conference event at the 39th International Conference of the Croatian Association for Applied Linguistics.
The workshop will take place on June 11, from 9:00 to 13:00, at the Faculty of Humanities and Social Sciences, University of Zagreb. Participation is free of charge. The workshop will be given in Croatian language.
Registration is required by June 3. More information and the registration link are provided here.
Convened by Slobodan Beliga, Ivana Filipović Petrović, and Jelena Parizoska, the workshop focuses on the comparative analysis of linguistic data derived from traditional corpora and outputs generated by large language models. Special attention will be given to South Slavic languages and the handling of phraseme constructions. Participants will compare results retrieved from the CLASSLA-web corpora (using the CLARIN.SI NoSketch Engine concordancer) with those generated through platforms that use large language models (such as ChatGPT).
The workshop pursues two main objectives: to evaluate the effectiveness of language technologies in handling low- and medium-resource languages, and to explore their potential in processing complex multi-word expressions and semantic ambiguity.
You can find more information about this CLASSLA-Express workshop, as well as upcoming workshops in the coming months, at the following link: https://www.clarin.si/info/k-centre/workshops/classla-express/
We hope to see you there!
April 2, 2025 – CLASSLA-Express is back!
We are excited to announce the next iteration of CLASSLA-Express workshops, a hands-on series designed to explore the use of CLASSLA-web corpora in linguistic research!
After a successful 2024 edition, which included workshops in 8 cities across 5 countries (see the reports here), this year, the CLASSLA-Express route has expanded to include an additional country and 3 new cities: Klagenfurt and Graz in Austria, and Bled in Slovenia. In addition, the CLASSLA-Express series will visit Zagreb and Rijeka in Croatia again, now with a new focus. The workshops will continue to explore corpus-linguistic research using CLASSLA-web corpora for South Slavic languages, while also testing how large language models (LLMs) perform linguistic tasks, integrating thereby AI tools with traditional methods.
This years’ iteration offers two workshop formats:
- CLASSLA-Express 1.0 that provides an introduction to corpus-linguistic research methods, exploring word meanings, collocations, and lexico-grammatical patterns in different text types.
- CLASSLA-Express 2.0 that focuses on the application of LLMs to linguistic tasks, comparing AI-based approaches with traditional corpus methods and contributing to the development of a framework for combining the two toolsets.
Workshops are free of charge and open to university students, linguists, lexicographers, language teachers, digital humanities scholars, and others.
Key dates for CLASSLA-Express workshops in 2025:
- 4 April 2025 – CLASSLA-Express 1.0 in Klagenfurt, Austria (University of Klagenfurt).
- 11 June 2025 – CLASSLA-Express 2.0 in Zagreb, Croatia, as part of HDPL 2025 (Faculty of Humanities and Social Sciences, University of Zagreb).
- 10 October 2025 – CLASSLA-Express 1.0 in Graz, Austria (Institute for Slavic Studies, University of Graz).
- 5 November 2025 – CLASSLA-Express 2.0 in Rijeka, Croatia, as part of CLARC 2025 (Faculty of Humanities and Social Sciences, University of Rijeka).
- 17 November 2025 – CLASSLA-Express 2.0 in Bled, Slovenia, as part of the eLex 2025 conference (Rikli Balance Hotel).
For details and registration, visit the CLASSLA-Express website.
We hope to see you at one of the workshops!
The CLASSLA-Express team: Jelena Parizoska, Ivana Filipović Petrović, Petya Osenova, Taja Kuzman and Nikola Ljubešić

December 18, 2024 – CLASSLA Annual Recap: 2024 in Review
As the year comes to a close, we would like to share a brief summary of the main activities and progress made at the CLASSLA Knowledge Centre for South Slavic Languages during 2024.
CLASSLA web corpora for South Slavic languages
This year, we set up a crawling infrastructure for the (bi)annual collection of web corpora for South Slavic languages – the CLASSLA-web corpora collection. The first version of corpora, CLASSLA-web 1.0, comprising 11 billion words in 7 languages, was included to the CLARIN.SI concordancers in 2023 and released on the CLARIN.SI repository this year. The web corpora are linguistically annotated with an improved CLASSLA-Stanza tool for linguistic annotation of South Slavic languages (available as a service here) and a multilingual genre classifier X-GENRE. Owing to their large size and recency, the CLASSLA-web corpora have already shown to be very useful for the development of large language models for South Slavic languages, and were included in the training datasets for the GaMS (Generative Model for Slovene) model and the YugoGPT model for Bosnian, Croatian, and Serbian. The next version of the CLASSLA web corpora has already been collected, and the release is planned for 2025.
CLASSLA-Express workshop series
In collaboration with Ivana Filipović Petrović, Jelena Parizoska and Petya Osenova, we organized seven CLASSLA-Express workshops in five South Slavic countries, attended by over 120 participants. The workshops focused on introducing concordancers, CLASSLA-web corpora, and CLARIN.SI services to linguists, lexicographers, language teachers, digital humanities scholars, and students. Feedback was extremely positive, and we are planning additional workshops for 2025, with sessions to be held in Bulgaria, Croatia, and Slovenia, as well as expanding beyond the South Slavic region to locations such as Austria. The workshops will also feature new topics, including the application of large language models in corpus linguistics and lexicography. Stay tuned for more details about the upcoming workshops!
Benchmarking LLMs for South Slavic languages and dialects
The rapid advancements in large language models have also reached South Slavic languages, and evaluation of their capabilities has become crucial to understand the strengths and limitations of these models for our languages, and to guide future development in both academic and applied settings. To this end, we benchmarked large language models for South Slavic languages and dialects, including the Torlak, the Chakavian, and the Cerkno dialect, on the task of commonsense reasoning. The results showed impressive capabilities of GPT models in handling South Slavic languages, showcasing not only their strong performance but also their ability to adapt to dialects. Remarkably, these models achieved high levels of accuracy in target dialects when provided with only a handful of examples. We are excited to continue our benchmarking activities as part of the LLM4DH and LLMs4EU projects, which will extend over the next few years.
Speech technologies
We continued dipping our toes into the world of speech technology. Our efforts included the development of the automatic speech recognition (ASR) system tailored to the Chakavian dialect based on the Mići Princ dataset. We also worked on the Mezzanine, ParlaSpeech and Mak na konac projects, which focus on developing spoken corpora and benchmarking speech technologies for Slovenian, Croatian and Serbian. In addition to developing various speech technologies, such as the classifier for filled pauses in speech (eem) that works splendidly for a series of South Slavic languages, we started building the CLASSLA infrastructure for speech research by publishing ParlaSpeech corpora also on concordancers. We are currently working on further enriching these corpora with disfluency information, primary stress position, and boundaries of prosodic units.
Sharing knowledge on language resources for South Slavic languages
As a knowledge centre, one of our core activities is sharing valuable information and supporting users in their work with language resources and technologies. Over the past year, we have responded to numerous helpdesk inquiries regarding access to resources and their use. In addition to providing direct support, we also maintain informative materials to help users navigate available resources – the CLASSLA FAQs for Slovenian, Croatian, Serbian, Bulgarian, and Macedonian. Furthermore, we released a new overview of Slovenian language technologies, summarizing the state-of-the-art language technologies for Slovenian.
Monitoring the usage of language resources
We also actively supported our parent organization, CLARIN.SI, by monitoring the usage of freely accessible language resources and concordancers provided by the CLARIN.SI infrastructure. This allowed us to gain valuable insights into which datasets, technologies, and corpora are used the most. We were pleased to discover significant usage from outside Slovenia, with users frequently querying corpora in over 18 different languages. We invite you to watch a brief 1-minute video presenting key statistics, including the number of visits, most popular resources, and a closer look at concordancer usage.
We are also very happy with the uptake of our Hugging Face page from where our ParlaSpeech corpora have been downloaded more than 6,000 times in the last few months. Our models are also heavily used, with the recently published multilingual IPTC news topic classifier being downloaded almost 13,000 times in the past four months.
We would like to take this opportunity to thank all our collaborators for another incredibly productive year and to express our gratitude to you for staying engaged with our activities. We look forward to another year of exciting developments and continued collaboration. Wishing you all a successful and fulfilling year ahead, both professionally and personally.
May 6, 2024 – CLASSLA-Express Workshops in North Macedonia, Bulgaria and Slovenia
This year, we are organizing the CLASSLA-Express workshop series: six workshops in 5 countries designed to demonstrate the practical applications of the CLASSLA web corpora in language research. The first two workshops have already taken place in Zagreb and Rijeka – see the report on how well it went – and the registration for the May workshop in Belgrade is now closed as we have already reached the maximum capacity.
We are very happy to announce that since the start of the series, we have added an additional stop to the workshop series: in June, we will also visit Sofia (Bulgaria) at the International CLaDA-BG Conference 2024, which was arranged in collaboration with the CLaDa-BG research infrastructure, a member of the CLASSLA knowledge centre.
Registration for the next three CLASSLA-Express workshops in Skopje, Sofia and Ljubljana is now open! Here are the details on the workshops:
- 4 June 2024 – CLASSLA-Express stop in Skopje, North Macedonia (Blaže Koneski Faculty of Philology, Ss. Cyril and Methodius University). Register here. More information about the programme and location is available here.
- 26 June 2024 – CLASSLA-Express stop in Sofia, Bulgaria (International CLaDA-BG Conference 2024). Register here. More information about the programme and location is available here.
- 18 September 2024 – CLASSLA-Express stop in Ljubljana, Slovenia (Language Technologies & Digital Humanities Conference 2024, University of Ljubljana). Register here. More information about the programme and location is available here.
The workshops, which are free of charge, will provide hands-on experience in using the CLARIN.SI NoSketch Engine concordancer to extract valuable insights on word meanings, usage, collocations, and grammatical patterns from Bulgarian, Macedonian, and Slovene corpora. The workshops are tailored for university students of South Slavic languages, linguists, lexicographers, language teachers, and digital humanities scholars.
We warmly welcome you to join us at the nearest workshop location. For further details, please visit https://www.clarin.si/info/k-centre/workshops/classla-express/.
April 15, 2024 – Mići Princ meets the Whisper ASR model
As you might have noticed, recently, we extended our efforts of providing language resources and technologies from standard South Slavic languages to South Slavic dialects as well (you might have heard about the COPA datasets in Cerkno, Torlak and Chakavian dialects which are the stars of the DIALECT-COPA unshared task at the VarDial 2024 workshop in Mexico City). Now, we are pleased to announce the first resources for speech technologies for Chakavian micro-dialects of Croatian: the Mići Princ dataset and an automatic speech recognition model for Chakavian, both openly available.
The Mići Princ dataset is a “text and speech” dialectal translation of Antoine de Saint-Exupéry’s “Le Petit Prince” (The Little Prince) into various Chakavian micro-dialects, released by the Udruga Calculus and the Peek&Poke museum, both in form of a printed book and an audio book. Almost every character in the book was translated and narrated into a different micro-dialect (for which we would like to thank again the large team of translators and audio book narrators behind this, especially the main translator, Tea Perinčić).
Following the creation of the Mići Princ dataset, our colleagues Peter Rupnik and Nikola Ljubešić aligned the text and speech to develop the first openly-available dataset for Chakavian automatic-speech recognition (ASR). The dataset is published on the CLARIN.SI repository, as well as on Hugging Face, where you can listen to it.
Moreover, we are pleased to introduce an innovative outcome derived from this dataset: Whisper-large-v3-mici-princ, an automatic speech recognition model for Chakavian. Through fine-tuning OpenAI’s Whisper model on the Mići Princ dataset, we achieved a great character-error-rate reduction of 66%. You are welcome to try it out on Hugging Face!
March 26, 2024 – CLASSLA-Express Workshops in Croatia, Serbia, North Macedonia and Slovenia
We are excited to announce a series of five workshops designed to demonstrate the practical applications of the CLASSLA web corpora in language research. The CLASSLA-Express workshops will take place from April to September 2024 in 4 countries and 5 cities: Croatia (Zagreb and Rijeka), Serbia (Belgrade), North Macedonia (Skopje) and Slovenia (Ljubljana). The workshops will provide hands-on experience in using the CLARIN.SI NoSketch Engine concordancer to extract valuable insights on word meanings, usage, collocations, and grammatical patterns from Croatian, Macedonian, Serbian and Slovene corpora. The workshops are free of charge.
The workshops are tailored for university students of South Slavic languages, linguists, lexicographers, language teachers, and digital humanities scholars.
The registration is already open for the workshops in Zagreb, Rijeka and Belgrade! We will make sure to let you know when the registrations in Skopje and Ljubljana open as well.
Here are the details of the workshops:
- 19 April 2024 – CLASSLA-Express stop in Zagreb, Croatia (Faculty of Humanities and Social Sciences, University of Zagreb). More information about the programme and location is available here.
- 26 April 2024 – CLASSLA-Express stop in Rijeka, Croatia (Center for Language Research, Faculty of Humanities and Social Sciences, University of Rijeka). More information about the programme and location is available here.
- 29 May 2024 – CLASSLA-Express stop in Belgrade, Serbia (International conference Leksikografski susreti, Faculty of Philology, University of Belgrade). More information about the programme and location is available here.
- 4 June 2024 – CLASSLA-Express stop in Skopje, North Macedonia (Blaže Koneski Faculty of Philology, Ss. Cyril and Methodius University). Registration is not open yet – we will let you know when it opens.
- 18 September 2024 – CLASSLA-Express stop in Ljubljana, Slovenia (Language Technologies & Digital Humanities Conference 2024, University of Ljubljana). Registration is not open yet – we will let you know when it opens.
We warmly welcome you to join us at the nearest workshop location. For registration and further details, please visit https://www.clarin.si/info/k-centre/workshops/classla-express/.
We would also like to kindly ask you to spread the word among researchers, students and other interested colleagues.
The CLASSLA-Express team: Ivana Filipović Petrović, Jelena Parizoska, Taja Kuzman and Nikola Ljubešić
December 24, 2023 – Updates on new Macedonian resources, and South Slavic endeavours to develop LLMs and ASR models
This year has been extremely packed with activities, hence this very last-minute cheer – we are on a good track to become much less of a less-resourced language family! We give a few examples that come to mind first.
December 6, 2023 – Comparable web corpora CLASSLA-web for all South Slavic languages
We are delighted to announce the release of comparable web corpora for all official South Slavic languages, namely Slovenian, Croatian, Bosnian, Montenegrin, Serbian, Macedonian and Bulgarian, all the corpora summing up to almost 11 billion words! The corpora are freely available on the CLARIN.SI NoSketch Engine concordancer (see our recent tutorial on how to easily query the CLASSLA web corpora and perform statistical analyses via the concordancer).
This collection of corpora is very innovative, due to the following reasons:
- This is, to the best of our knowledge, the first collection of comparable web corpora covering a whole language group.
- The collection includes the first general, linguistically annotated corpora for two out of seven languages, namely Montenegrin and Macedonian.
- The comparability of the corpora is ensured by performing data collection and filtering in the same time period with the same technologies. Furthermore, the corpora underwent a uniform linguistic processing via the CLASSLA-Stanza toolkit, which you can now try out also through the CLASSLA annotator web interface.
- Each of the documents in each of the corpora is annotated with the X-GENRE multilingual genre classifier.
For more details, we warmly invite you to read our new blog post which introduces the CLASSLA-web corpora. The blog post provides more details on the corpora sizes and interesting insights on the correlations between genre distributions and GDP per capita across the seven South Slavic countries.
We will be very glad to obtain feedback on our corpora and annotation technology. As usual, please write to us on helpdesk.classla@clarin.si!
These corpora would not have been released without great collaboration inside the CLASSLA Knowledge centre for South Slavic languages, which includes the Slovenian consortium CLARIN.SI, the Institute of Croatian Language, and the Bulgarian consortium CLADA-BG. Furthermore, very crucial were the longstanding collaboration with the ReLDI centre on a series of South Slavic languages, and Biljana Stojanovska and Katerina Zdravkova on Macedonian. On this occasion, we want to thank everyone for the collaboration, and invite others to join our common efforts!
September 13, 2023 – New state-of-the-art version of CLASSLA-Stanza pipeline for linguistic processing of South Slavic languages
We are delighted to announce the release of an improved CLASSLA-Stanza pipeline, which enables state-of-the-art linguistic processing of Slovenian, Croatian, Serbian, Macedonian and Bulgarian language.
In addition to covering standard varieties of five South Slavic languages, the pipeline also provides special modules for linguistic annotation of non-standard text and web corpora for Slovenian, Croatian and Serbian. The CLASSLA-Stanza annotation tool supports a total of six tasks: tokenization, morphosyntactic annotation, lemmatization, dependency parsing, semantic role labeling, and named-entity recognition. Some of the main improvements that separate CLASSLA-Stanza from the Stanza pipeline are:
- support of external inflectional lexicons which significantly increases performance on morphologically rich languages;
- extended training datasets (beyond Universal Dependencies data) for all included models;
- use of CLARIN.SI-embed word embeddings, trained on significantly larger and more diverse datasets than embeddings used by Stanza;
- specific modules for standard, non-standard and web text.
As a result, we are happy to report that the CLASSLA-Stanza significantly outperforms Stanza, with error reduction between 34% and 98% on the Slovenian official benchmark (see table below which reports the performance using the Micro F1 score). You can find more details on the pipeline improvements and training settings in a technical report “CLASSLA-Stanza: The Next Step for Linguistic Processing of South Slavic Languages” (Terčon & Ljubešić, 2023).
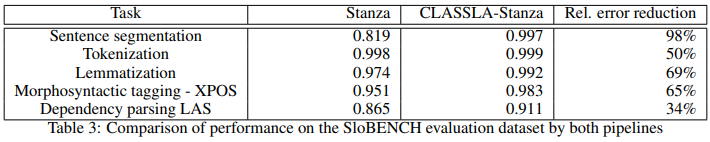
You can use CLASSLA-Stanza as a python library (documentation is available here) or via an online service (currently available for Slovenian, other languages and modules coming soon). Separate models are also freely available at the CLARIN.SI repository.
These results would not be possible without immense efforts in developing high-quality training datasets together with our collaborators all around Europe. We wish to use this opportunity to most warmly thank all of them!
June 23, 2023 – CLASSLA web corpora of Croatian, Serbian and Slovenian
We are delighted to announce the release of the pilot versions (v0.1) of the CLASSLA web corpora for Croatian (2.3 billion words), Serbian (2.4 billion words) and Slovenian (1.9 billion words). The main features of the newly released corpora, aside from their massive size and recency (crawled in 2022) is their automatic enrichment with genre information and their linguistic processing with the improved CLASSLA-Stanza annotation pipeline (applied version to be released soon). The corpora are available for search via the CLARIN.SI concordancers, Crystal NoSketchEngine, Bonito NoSketchEngine and KonText. The pilot versions of these corpora are intended to gather valuable user feedback, while the official release (v1.0) of the three existing corpora, along with web corpora for Bosnian, Montenegrin, Macedonian, and Bulgarian, is scheduled for later this year.
We warmly welcome you to explore our corpora. Please reach out to us at helpdesk.classla@clarin.si with any ideas for improvements — we will try hard to implement them in the upcoming official release already! We also encourage you to share with us how you plan to use these corpora in your research, as well as any other use cases you may have in mind.
To give you some ideas on how the corpora can be used in your research you are invited to read our blog post on the use of CLASSLA web corpora via the open CLARIN.SI concordancers. The step-by-step tutorial covers a wide range of functionalities of the concordancers, including finding collocations in different genres, analyzing word statistics, and exploring the use of non-standard words. This resource is particularly suited for linguists, language teachers and digital humanists.
April 25, 2023 – A web corpus intermezzo
We were keeping rather silent for some time now due to many developments that required our full capacity. But you can expect reports on interesting resources, tools, and experiments in the following months!
We were, however, not the only ones who were very busy in the previous period. Philipp Wasserscheidt has recently published the PDRS web corpus of Serbian language, 715 million tokens in size. You can find more details on the corpus in the CLARIN.SI repository entry where the corpus is available for download. The corpus is also available via the CLARIN.SI concordancers.
Philipp is also making sure that future users know how to use the corpus. This is slightly last-minute, but maybe still not too late for some of you – a workshop on the PDRS web corpus usage will be held from this Thursday to Saturday in Belgrade. More information is available at https://javnidiskurs.rs/poziv-na-radionicu-pdrs-1-0/.
Since we are on the topic of web corpora, we have two pieces of news to share right away as well:
1. The head of the CLASSLA centre, Nikola Ljubešić, has taken one of the leading roles in the ACL Special Interest Group for Web as a Corpus (SIGWAC). If you are interested in this area of research, you should join the SIG by signing up to the mailing list.
2. We are in the process of releasing the MaCoCu datasets, which are web crawls of various national top-level domains, including those of Slovenia, Croatia, Bosnia and Herzegovina, Montenegro, Serbia, Macedonia and Bulgaria. We are sharing here the link just to the Macedonian dataset. Linguistic processing of the datasets has just started, and will result in the CLASSLA web corpora, to be updated on a biyearly basis.
December 22, 2022 – Looking forward to 2023!
We wanted to wish all of you happy holidays and a successful 2023. To wrap-up a very busy, but also a very successful 2022, we are sharing with you what we will be releasing in the first half of the next year.
We are working on releasing a new version of our CLASSLA-Stanza tool, with the following improvements:
- Minor improvements on usability and programming interface
- New Slovenian models for standard and Internet non-standard language, but also for spoken language (transcripts), most of the improvements being the results of the VERY successful RSDO project
- New standard and non-standard models for Croatian and Serbian, as we are constantly working on improving our data (it is a never-ending game)
- Drastically improved standard model for Macedonian (we resolved numerous errors by extending the training data (previous model was trained only on an Orwell’s novel))
- We will also release the tool through a web interface and a web service, similar to the RSDO interface for linguistic processing of Slovenian (which also uses CLASSLA-Stanza)
Inside the ParlaMint project we are working hard on releasing parliamentary corpora for the Slovenian, Croatian, Bosnian, Serbian and Bulgarian parliaments, which is one of the big coordination successes of the CLASSLA K-centre. Just for comparison, in the first iteration of the ParlaMint corpus, there was only one term of the Croatian parliament covered, while now the corpus will cover six terms. Bosnian and Serbian were not part of the first iteration of the ParlaMint corpus.
Finally, we will also publish our new generation of web corpora, called CLASSLA-web. We already have prepared the raw data for Slovenian (1.8 billion words), Croatian (2.3 billion words), Macedonian (524 million words), and Bulgarian (3.5 billion words), but will release the corpora both for download and through concordancers once we have all the languages fully processed (we are currently processing Bosnian, Montenegrin and Serbian) and data annotated with the latest version of CLASSLA-Stanza.
October 19, 2022 – Our recent activities on speech
We wanted to share with you our recent results on speech processing, something we mentioned will be one of our foci in 2022.
We released two speech datasets. One is in Croatian, the ParlaSpeech-HR dataset, 1816 hours of recordings in size, with accompanying transcriptions and speaker metadata. The dataset is based on the ParlaMint corpus of Croatian parliamentary proceedings. The other dataset is in Serbian, the JuzneVesti-SR dataset, “only” 50 hours in size. It consists of audio recordings and transcripts from the Južne Vesti website and its host show called 15 minuta, with speaker metadata available as well. With each of the datasets, we released also automatic speech recognition (ASR) models on HuggingFace, four Croatian ASR models for the ParlaSpeech-HR dataset, with excellent (but in-domain) word error rate of only 4%, and for now one Serbian ASR model for the JuzneVesti-SR dataset. You are more than welcome to take any of the models or data (all are available under CC-BY-SA). Interestingly, our speech-related efforts were very quickly picked up by the industry as well, featuring our speech and text technologies in a recent blog.
We also published two papers, one on the overall approach to building the ParlaSpeech-HR dataset, another on performing benchmarking for user profiling over the ParlaSpeech-HR dataset.
Given the recent successes in acquiring funding for performing more research on spoken data, in the following years we will be researching many super-interesting speech-related tasks, including:
- word-level clustering of types of pronunciation and extraction of prototypical pronunciations
- linguistic processing of transcripts of spoken data, potentially informed by the speech signal itself
- disfluency identification and classification
- dialogue act classification
- identifying ways to build large and cheap spoken corpora of South Slavic languages
Please do get in touch if you are interested, or already working on speech. Also, we invite similar e-mails – drafting future activities – from other sides as well! We need coordination between different efforts, something we discussed to great length in our recently published book chapter.
May 6, 2022 – Massive monolingual and parallel South Slavic corpora freely available
We are happy to announce that new high-quality monolingual and parallel web corpora for South Slavic languages have been released. The corpora were created in scope of the MaCoCu project, which focuses on collecting monolingual and parallel data from the Internet for European under-resourced languages, South Slavic languages included.
The datasets were built by crawling the national top-level domains, extending the crawl dynamically to other domains as well. More information on the corpora construction and links to the freely-available tools that were used for crawling and cleaning can be found in the description of resources, published on the CLARIN.SI repository (see links below).
The following new South Slavic corpora are freely available from the CLARIN.SI repository:
- Croatian web corpus MaCoCu-hr 1.0 with 2.3 billion words in 7 million texts;
- Slovene web corpus MaCoCu-sl 1.0 with 1.8 billion words in 5.8 million texts;
- Macedonian web corpus MaCoCu-mk 1.0 with 0.5 billion words in 1.96 million texts;
- Bulgarian web corpus MaCoCu-bg 1.0 with 3.5 billion words in 10.5 million texts;
- Croatian-English parallel corpus MaCoCu-hr-en 1.0 with 135 million words in 3 million segments (sentence pairs);
- Slovene-English parallel corpus MaCoCu-sl-en 1.0 with 137 million words in 3 million segments;
- Macedonian-English parallel corpus MaCoCu-mk-en 1.0 with 24 million words in 0.48 million segments;
- Bulgarian-English parallel corpus MaCoCu-bg-en 1.0 with 159 million words in 3.9 million segments.
We are already working on using the above datasets for BERT-like language model pre-training, and producing linguistically-annotated corpora that will be available through our concordancers. Next year, the corpora will be upgraded and additional South Slavic monolingual and parallel corpora will be released, i.e., Bosnian, Serbian and Montenegrin.
April 20, 2022 – First open speech-to-text system and ASR training dataset for Croatian
The first open speech-to-text system for Croatian is now available in the Hugging Face model hub. The system is currently based on 72 hours of transcripts of parliamentary debates from the Croatian parliament. The ASR training dataset for Croatian ParlaSpeech-HR v1.0 is freely available in the CLARIN.SI repository. The dataset and the system were developed by Nikola Ljubešić, Ivo-Pavao Jazbec, Vuk Batanović, Lenka Bajčetić, Danijel Korzinek and Peter Rupnik. These results would not have been possible without a wider collaboration around the ParlaMint project, and for that Darja Fišer, Tomaž Erjavec, Maciej Ogrodniczuk and Petya Osenova are to be thanked.
December 21, 2021 – CLASSLA in Tour de CLARIN
CLASSLA has been presented by Tour de CLARIN, a CLARIN ERIC initiative which presents its national consortiums, Knowledge Centres and Service Providing Centres (B-centres). Find out more about CLASSLA’s activities, services and its mission here. The new volume of Tour de CLARIN also includes an interview with Zrinka Kolaković in which she shares how she uses our corpora and tools to research South Slavic clitics and aspect. Read more here.
December 13, 2021 – Workshop on regional markedness in text
On 6 and 7 November 2021, an online workshop on regional markedness in text took place, organised by the ReLDI centre, University of Zurich, and CLASSLA. The materials from the workshop are now available here. They provide a gentle introduction to querying the corpora through the noSketchEngine and KonText concordancers, using the Corpus Query Language (CQL) syntax and morphosyntactic descriptions (MSDs) to analyse gender bias in society.
November 26, 2021 – Success Stories
A new entry has been added to the CLARIN Knowledge Centre for South Slavic languages (CLASSLA). In Success stories, we present activities where collaboration resulted in important language resources for Slovenian, Croatian and Serbian, created with a fraction of the full costs by exploiting the large synergistic potential of South Slavic languages. These are the stories that motivated the creation of CLASSLA.
![]()