
Update: The current state-of-the-art in linguistic processing of South Slavic languages is the CLASSLA python package that deals with the same levels of processing as this web service, but for an extended list of South Slavic languages, and with significantly improved performance. You can test the CLASSLA-Stanza library through the CLASSLA annotator web interface.
CLARIN.SI hosts a text annotation service named ReLDIanno that enables processing of three South Slavic languages: Slovenian, Croatian and Serbian. There are two main ways of using ReLDIanno: (1) through a web application and (2) through a Python library. Some of the tools available through the web application/library were developed within the ReLDI and JANES projects.
Web application
The web application can be found at: http://clarin.si/services/web/. It has two basic funcionalities: Tagger and Lexicon.
Tagger
The Tagger is an online text-processing tool which allows you to perform four different types of linguistic annotation: morphosyntactic tagging, lemmatisation, named entity recognition (NER), and Universal Dependency (UD) parsing.
Language
Before starting, please make sure that you have selected one of the three available languages from the Language drop-down menu: Croatian, Serbian, or Slovenian.
Format
Next, select one of the two options in the Format field: Text or TCF. The Text option represents plain-text formatting, while TCF stands for Text Corpus Format, which is a file format that enables different types of linguistic annotation to be stored within one document. (More information on TCF can be found here.)
Text
The Text field allows you to input text by typing it directly, or by copying it from another document.
File
Alternatively, you can upload an existing document by clicking on the Choose File button. The supported file formats for upload are: plain text files (.txt), Word files (.doc/.docx), PDF files (.pdf) and ZIP archives (.zip). ZIP archives can contain any combination of the other three input file types. The only supported text format for uploaded files is plain text.
If you want to change the file you have uploaded, you can do so by clicking on the Remove button. This will clear the selection and allow you to upload another file.
Function
The Function field contains a selection of the four different annotation processes:
1. Tag
The Tag option provides morphosyntactic descriptions, in the form of an MSD (morphosyntactic description) tag for each token.
| Surface | Tags | |
| 1. | Gosti | Ncmpn |
| 2. | su | Var3p |
| 3. | stigli | Vmp-pm |
| 4. | . | Z |
The MSD tag Ncmpn, for example, tells us that the word gosti is a common noun (Nc) of masculine gender (m) and is plural (p) and in the nominative case (n).
Tagset: There is a complete list of MSD tags and their features for each language — Croatian, Serbian, and Slovenian.
Accuracy: Croatian (92.53%), Serbian (92.33%), Slovenian (94.27%).
References:
- Nikola Ljubešić, Tomaž Erjavec (2016). Corpus vs. Lexicon Supervision in Morphosyntactic Tagging: the Case of Slovene. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). Portorož, Slovenia. [Link] [.bib]
- Nikola Ljubešić, Filip Klubička, Željko Agić, Ivo-Pavao Jazbec (2016). New Inflectional Lexicons and Training Corpora for Improved Morphosyntactic Annotation of Croatian and Serbian. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). Portorož, Slovenia. [Link] [.bib]
2. Lemmatise
The Lemmatise option provides a lemma, also known as the citation or dictionary form of a word. The process of lemmatization yields a single form which stands for different inflected forms of one word.
| Surface | Lemma | |
| 1. | Gosti | gost |
| 2. | su | biti |
| 3. | stigli | stići |
| 4. | . | . |
For instance, in the case of the noun gosti, its lemma is the nominative singular form gost. The lemma of a verb is its infinitive form, in this case biti and stići.
For uninflected words, the lemma will remain the same as the surface form. This is also the case with digits and punctuation marks.
Accuracy: >99.5% for all three languages.
References: unpublished.
3. NER
NER (Named entity recognition) is a process through which named entities that appear in a text are located and categorized.
| Surface | NER | |
| 1. | Barak | B-Per |
| 2. | Obama | I-Per |
| 3. | je | O |
| 4. | bio | O |
| 5. | 44. | O |
| 6. | predsednik | O |
| 7. | SAD | B-Loc |
| 8. | . | O |
Named entities (NEs) are classified into five categories: person (PER), person derivative (DERIV-PER), location (LOC), organization (ORG), and miscellaneous (MISC).
The NER in the Tagger uses the IOB2/BIO format, which means that, in multiword NEs (e.g. Barak Obama), the first item in a chunk is marked with a B-tag (beginning) and all subsequent items in the same chunk are assigned the I-tag (inside). Single-word NEs are marked with the B-tag (e.g. SAD), while tokens that are not NEs are tagged with O (outside).
Tagset: The NER annotation guidelines can be found here.
Accuracy: evaluated on Slovene data, the PER class has F1 of 0.91, LOC of 0.79, ORG of 0.57, DERIV-PER of 0.49 and MISC of 0.3.
References:
- Darja Fišer, Nikola Ljubešić and Tomaž Erjavec (2018). The Janes project: language resources and tools for Slovene user generated content. Language Resouces and Evaluation. [Link] [.bib]
- Nikola Ljubešić, Marija Stupar, Tereza Jurić and Željko Agić (2013). Combining Available Datasets for Building Named Entity Recognition Models of Croatian and Slovene. Slovenščina 2.0.[Link] [.bib]
4. Dep Parse
The Dep Parse (dependency parsing) option refers to the annotation of Universal Dependencies (UD). UD annotation, which is part of the Universal Dependencies project, entails both morphological and syntactic annotation.
The morphological portion of UD annotation consists of a lemma, part-of-speech (POS) tag, and a set of features encoding grammatical and lexical properties. (Since this information is already provided by the Tag and Lemmatise options, it is not included in the Tagger’s Dep Parse option.)
The syntactic portion is a description of the syntactic structure of a sentence by means of directed binary relations, referred to as dependencies, between its words. Each word “depends” on another word in the sentence, apart from the one marked as ‘root’, which is taken to be the center of the sentence.
As shown in the table below, every tag in the ‘Dep parse’ column consists of a number (gov) and an abbreviation (func). For example, the adjective stoni (token 3) is governed by (i.e. depends on) the noun tenis (token 4) and functions as its adverbial modifier, which is why its tag is ‘4 / amod’. The noun tenis (token 4) is, in turn, governed by the verb igra (token 2), but serves the function of its direct object, thus being tagged as ‘2 / dobj’. This verb also happens to be the so-called center of the sentence, and is tagged as ‘0 / root’.
Since Petar igra stoni tenis, a Ana trenira plivanje is a complex sentence, its constituent clauses have to be connected to one another. This is why the center of the second clause, the verb trenira (token 8) is marked as being dependent on the center (root) of the entire sentence (token 2), which is located in the first clause. Because the sentence consists of two independent clauses in coordination, the second clause functions as a conjunct of the first one, and trenira is tagged as ‘2 / conj’.
| Surface | Dep parse – gov / func | |
| 1. | Petar | 2 / nsubj |
| 2. | igra | 0 / root |
| 3. | stoni | 4 / amod |
| 4. | tenis | 2 / dobj |
| 5. | , | 2 / punct |
| 6. | a | 2 / cc |
| 7. | Ana | 8 / nsubj |
| 8. | trenira | 2 / conj |
| 9. | plivanje | 8 / dobj |
| 10. | . | 2 / punct |
Tagset: The list of UD relations can be found here.
Accuracy: Croatian (~0.9 UAS, ~0.86 LAS), Serbian (~0.92 UAS, ~0.88 LAS), Slovenian (~0.87 UAS, ~0.86 LAS). These are gross estimates and are heavily dependent on the specificity of test data for each language.
References:
- Željko Agić and Nikola Ljubešić (2015). Universal Dependencies for Croatian (that Work for Serbian, too). Proceedings of the 5th Workshop on Balto-Slavic Natural Language Processing (BSNLP 2015). Hissar, Bulgaria. [Link] [.bib]
- Tanja Samardžić, Mirjana Starović, Željko Agić, Nikola Ljubešić (2017). Universal Dependencies for Serbian in Comparison with Croatian and Other Slavic Languages. Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing (BSNLP 2017). Valencia, Spain. [Link] [.bib]
N.B. The Tag and Lemmatise options can be chosen individually or in combination with one another. The NER and Dep Parse options always include the Tag and Lemmatise options.
Result
Once you have finished with text input/file upload and set the parameters of your query, click on the PROCESS button. To perform a different type of annotation on the same text, simply select a different process or combination of processes in the Function field and click on the PROCESS button again. If you want to change the chosen text, click on the CLEAR button first.
The Result field offers three different options:
- Table – The text is verticalized and presented in table form. Each token is located in a separate row. The first two columns are the token numbers and the tokens themselves, respectively. They are followed by columns containing tags, in the order that their respective annotations are listed in the Function field. The last two columns are the first and final character number of a given token within the given input text.
- Raw – The Raw view represents the way the text shown in the Table view is saved on the machine. The text is shown in JSON format. JSON is a file format used by machines to store and exchange data. It is easy both for humans to read and write and for machines to parse and generate. JSON is independent of any programming language, which makes it one of the best data-interchange formats. JSON attributes in the Raw view include information about sentences, tokens, text and annotation tags. The attribute “sentences” contains information about every sentence, the attribute “token” contains information about every token, while the attribute “text” contains the entire text from the Text field or the uploaded file. Attributes “POSTags”, “depparsing”, “lemmas” and “namedEntities” contain information about tags, with respect to the annotations selected in the Function field. (More information on JSON can be found here.)
- Download – This option allows you to download the result of your query in the form of a TSV (Tab-Separated Values) file. The sentence is verticalized and the columns are separated by the “tab” character. (However, please bear in mind that, unlike the Table view, there are no column headings.) Much like JSON, the TSV format is commonly used by machines to store and exchange data.
Lexicon
The Lexicon is an online inflectional lexicon of Croatian, Serbian and Slovenian. It is based on hrLex, srLex and Sloleks for Slovenian.
Language
Before starting, please make sure that you have selected one of the three available languages from the Language drop-down menu at the bottom of the page: Croatian, Serbian, or Slovenian.
Search parameters
Input
- Regular Input allows you to completely match a string (e.g. petosatni), or to use the % character as wildcard. For instance: pet% (pet, petodnevni, petostran, etc.), %pet (pet, napet, trepet, opet etc.), %pet% (any string containing the substring pet).
- Regex Input refers to the use of regular expressions. A regular expression is a type of string that contains special characters and is used to search for patterns. If you are, for instance, trying to find all verbs derived from the verb ljubiti, you can find them by searching for [a-ž]ljubiti. The search will yield results such as izljubiti, obljubiti, poljubiti, priljubiti, etc. This is because the range specified in the square brackets encompasses the entire alphabet.
A list of frequently used regular expressions with explanations can be found here.
Surface form
The surface form of a word is the form a word appears in in a given text. For instance, in the sentence Gosti su stigli, the surface form of the verb stići is stigli.
Lemma
A lemma (also known as the citation or dictionary form) is a single form which stands for different inflected forms of one word. For example, the lemmas of the words in the sentence Gosti su stigli are gost (the nominative singular form of the noun), biti and stići (the infinitive form of the verbs).
In the case of uninflected words, the lemma is the same as the surface form.
If you are unsure about the lemma of a particular word, please use the Tagger and select the Lemmatise option.
MSD
MSD tags contain morphosyntactic descriptions of words. In the sentence Gosti su stigli, the MSD tag for the word gosti is Ncmpn. This tag tells us that gosti is a common noun (Nc) of masculine gender (m) and is plural (p) and in the nominative case (n).
There is a complete list of MSD tags and their features for each language — Croatian, Serbian, and Slovenian.
No. of syllables
This option allows you to narrow down your search by limiting the number of syllables.
Result
Once you have set the parameters of your query, click on the FILTER button. To perform a new search, click on the CLEAR button first.
The results can be viewed in the form of a table, in which the first column is the surface form, followed by a MSD tag column and a lemma column, respectively. Choosing the Table view also allows you to search within the results.
In the Raw view, the results are presented in JSON format. (More information on JSON can be found here.)
References:
- Nikola Ljubešić, Filip Klubička, Željko Agić, Ivo-Pavao Jazbec (2016). New Inflectional Lexicons and Training Corpora for Improved Morphosyntactic Annotation of Croatian and Serbian. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). Portorož, Slovenia. [Link] [.bib]
Python library
The Python library can be found at: https://github.com/clarinsi/reldi-lib
Installing the library
The easiest way to install the ReLDI library is through PyPI from your command line interface.
$ sudo pip install reldi |
Using the library
Requirements
The library is run using Python 2. In Mac and Linux operating systems Python 2 is pre installed. If Python 2 is not pre installed, it is suggested to setup a virtual environment. For more information, please check the following link: https://conda.io/projects/conda/en/latest/user-guide/tasks/manage-python.html. In addition, be aware that server settings prevent the library from processing files larger than 8KB.
Scripts
restore_all.py
If you need diacritic restoration, you will want to use the restore_all.py script. You can observe the output of the script in the file examples/example.txt.redi.
$ python restore_all.py hr examples/example.txt
Notice that batch file processing is available, as well, by giving a directory as the second argument. Running the following command will process all files in the defined directory with the extension .txt.
$ python restore_all.py hr examples/
You can get more information by running:
$ python restore_all.py -h
tag_all.py
If you need tokenisation, morphosyntactic tagging and/or lemmatisation, you will want to use the tag_all.py script. You can inspect the output of the script in the file examples/example.txt.redi.taglem.
$ python tag_all.py hr examples/example.txt.redi
ner_all.py
If you need named entity recognition with morphosyntactic tagging and lemmatisation, you will use the ner_all.py script. You can inspect the output of the script in the file examples/example.txt.redi.tagNERlem.
$ python ner_all.py hr examples/example.txt.redi
parse_all.py
If you also need dependency parsing, you can use the parse_all.py script. The output of this script is available in the file examples/example.txt.redi.parse. The interface of all three scripts scripts is very similar.
$ python parse_all.py hr examples/example.txt.redi
Library
If you want to use the web service responses in your own code, the best option is to use the library directly. Below are some simple examples of the diacritic restorer and the tokeniser/tagger/lemmatiser from the Python interactive mode:
>>> import json
>>> from reldi.restorer import DiacriticRestorer
>>> dr=DiacriticRestorer('hr')
>>> dr.authorize('my_username','my_password')
>>> json.loads(dr.restore('Cudil bi se da ovo dela.'))
{'orthography': [{'tokenIDs': 't_0', 'ID': 'pt_0', 'value': '\xc4\x8cudil'}, {'tokenIDs': 't_1', 'ID': 'pt_1', 'value': 'bi'}, {'tokenIDs': 't_2', 'ID': 'pt_2', 'value': 'se'}, {'tokenIDs': 't_3', 'ID': 'pt_3', 'value': 'da'}, {'tokenIDs': 't_4', 'ID': 'pt_4', 'value': 'ovo'}, {'tokenIDs': 't_5', 'ID': 'pt_5', 'value': 'dela'}, {'tokenIDs': 't_6', 'ID': 'pt_6', 'value': '.'}], 'text': 'Cudil bi se da ovo dela.', 'tokens': [{'endChar': '5', 'startChar': '1', 'ID': 't_0', 'value': 'Cudil'}, {'endChar': '8', 'startChar': '7', 'ID': 't_1', 'value': 'bi'}, {'endChar': '11', 'startChar': '10', 'ID': 't_2', 'value': 'se'}, {'endChar': '14', 'startChar': '13', 'ID': 't_3', 'value': 'da'}, {'endChar': '18', 'startChar': '16', 'ID': 't_4', 'value': 'ovo'}, {'endChar': '23', 'startChar': '20', 'ID': 't_5', 'value': 'dela'}, {'endChar': '24', 'startChar': '24', 'ID': 't_6', 'value': '.'}], 'sentences': [{'tokenIDs': 't_0 t_1 t_2 t_3 t_4 t_5 t_6', 'ID': 's_0'}]}
>>> from reldi.tagger import Tagger
>>> t=Tagger('hr')
>>> t.authorize('my_username','my_password')
>>> json.loads(t.tagLemmatise(u'Ovi alati rade dobro.'.encode('utf8')))
{'tokens': [{'endChar': '3', 'startChar': '1', 'ID': 't_0', 'value': 'Ovi'}, {'endChar': '9', 'startChar': '5', 'ID': 't_1', 'value': 'alati'}, {'endChar': '14', 'startChar': '11', 'ID': 't_2', 'value': 'rade'}, {'endChar': '20', 'startChar': '16', 'ID': 't_3', 'value': 'dobro'}, {'endChar': '21', 'startChar': '21', 'ID': 't_4', 'value': '.'}], 'lemmas': [{'tokenIDs': 't_0', 'ID': 'le_0', 'value': 'ovaj'}, {'tokenIDs': 't_1', 'ID': 'le_1', 'value': 'alat'}, {'tokenIDs': 't_2', 'ID': 'le_2', 'value': 'raditi'}, {'tokenIDs': 't_3', 'ID': 'le_3', 'value': 'dobro'}, {'tokenIDs': 't_4', 'ID': 'le_4', 'value': '.'}], 'text': 'Ovi alati rade dobro.', 'POSTags': [{'tokenIDs': 't_0', 'ID': 'pt_0', 'value': 'Pd-mpn'}, {'tokenIDs': 't_1', 'ID': 'pt_1', 'value': 'Ncmpn'}, {'tokenIDs': 't_2', 'ID': 'pt_2', 'value': 'Vmr3p'}, {'tokenIDs': 't_3', 'ID': 'pt_3', 'value': 'Rgp'}, {'tokenIDs': 't_4', 'ID': 'pt_4', 'value': 'Z'}], 'sentences': [{'tokenIDs': 't_0 t_1 t_2 t_3 t_4', 'ID': 's_0'}]}
>>> from reldi.parser import Parser
>>> p=Parser('hr')
>>> p.authorize('my_username','my_password')
>>> json.loads(p.tagLemmatiseParse(u'Ovi alati rade dobro.'.encode('utf8')))
>>> from reldi.ner_tagger import NERTagger
>>> n=NERTagger('hr')
>>> n.authorize('my_username','my_password')
>>> json.loads(n.tag(u'Ovi alati u Sloveniji rade dobro.'.encode('utf8')))
>>> from reldi.lexicon import Lexicon
>>> lex=Lexicon('hr')
>>> lex.authorize('my_username','my_password')
>>> json.loads(lex.queryEntries(surface="pet"))
Code documentation
Code diagram
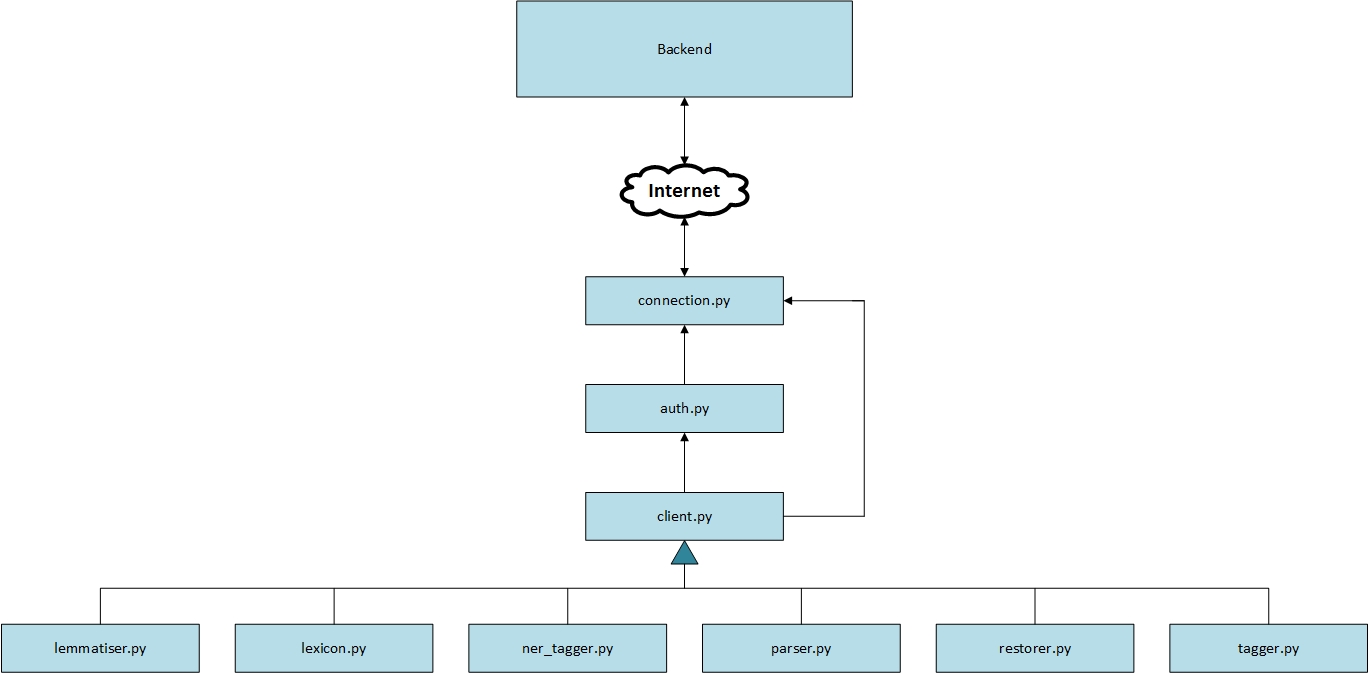
Source code description
The directory reldi contains the code of the library. The library can be run using this code or the scripts which represent an additional layer of user interface.
auth.py
The class that checks if authentication credentials are valid.
client.py
The class that queries the backend, if the authorization is successful. This is a base class that is derived by every specific purpose class (tagger, lexicon, etc).
connection.py
The class that directly communicates with the backend. Both auth.py and client.py use this class as a mediator between themselves and the backend.
lemmatiser.py
The class that lemmatises the input text. Derived from the Client class.
lexicon.py
The class that offers lexicon options. Derived from the Client class.
ner_tagger.py
The class that is used for named entity recognition. Derived from the Client class.
parser.py
The class that is used for dependency parsing. Derived from the Client class.
restorer.py
The class that is used for diacritic restoration. Derived from the Client class.
tagger.py
The class that is used for tagging and lemmatising. Derived from the Client class.
References
The papers describing specific technologies (that should be cited if any of them are used) are the following:
Tokenisation
Diacritic restoration
- Nikola Ljubešić, Tomaž Erjavec, and Darja Fišer (2016). Corpus-based diacritic restoration for south slavic languages. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). Portorož, Slovenia. [Link] [.bib]
- Diacritic restoration tool Github repository
MSD tagging
- Nikola Ljubešić, Tomaž Erjavec (2016). Corpus vs. Lexicon Supervision in Morphosyntactic Tagging: the Case of Slovene. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). [Link] [.bib]
- Nikola Ljubešić, Filip Klubička, Željko Agić, Ivo-Pavao Jazbec (2016). New Inflectional Lexicons and Training Corpora for Improved Morphosyntactic Annotation of Croatian and Serbian. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). Portorož, Slovenia. [Link] [.bib]
- MSD tagger and lemmatiser Github repository
Dependency parsing
- Željko Agić and Nikola Ljubešić (2015). Universal Dependencies for Croatian (that Work for Serbian, too). Proceedings of the 5th Workshop on Balto-Slavic Natural Language Processing (BSNLP 2015). Hissar, Bulgaria. [Link] [.bib]
- Tanja Samardžić, Mirjana Starović, Željko Agić, Nikola Ljubešić (2017). Universal Dependencies for Serbian in Comparison with Croatian and Other Slavic Languages. Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing (BSNLP 2017). Valencia, Spain. [Link] [.bib]
Named entity recognition
- based on the [janes-ner] NER tagger
- Darja Fišer, Nikola Ljubešić and Tomaž Erjavec (2018). The Janes project: language resources and tools for Slovene user generated content. Language Resouces and Evaluation. [Link] [.bib]
- Nikola Ljubešić, Marija Stupar, Tereza Jurić and Željko Agić (2013). Combining Available Datasets for Building Named Entity Recognition Models of Croatian and Slovene. Slovenščina 2.0. [Link] [.bib]
- NER tagger Github repository