CLASSLA K Centre Events
The following events, organised by CLASSLA, are presented below:
April to November 2025: CLASSLA-Express – Using CLARIN.SI corpora, resources, and AI tools in language research
From April to November 2025, the second iteration of the CLASSLA-Express workshops was held in 4 cities across 3 countries: Austria (Klagenfurt and Graz), Croatia (Zagreb), and Slovenia (Bled). This round not only expanded the geographic reach of the workshops but also introduced CLASSLA-Express 2.0 – a new edition focused on evaluating how large language models (LLMs) perform linguistic tasks and identifying which tasks are better suited to LLMs versus traditional corpus-based methods. More details on the CLASSLA-Express workshops are available here.
Report from the CLASSLA-Express 2.0 stop in Bled, November 2025
The final CLASSLA-Express 2.0 workshop of the year took place on 17 November in Bled, as a pre-conference workshop of the eLex 2025 conference. The event, titled Corpora vs. Large Language Models, brought together researchers interested in combining corpus methods with AI tools in lexicographic and phraseological work on South Slavic languages.
The workshop opened with four introductory talks. Slobodan Beliga offered an accessible introduction to large language models and generative AI, followed by Apolonija Gantar, who presented several examples of how AI tools are already being incorporated into Slovenian lexicography. Ivana Filipović Petrović then introduced the audience to the possibilities and limits of applying ChatGPT to Croatian phraseology and related lexicographic tasks. Jelena Parizoska followed with a presentation on what corpus-based methods offer linguists, highlighting the CLASSLA Knowledge Centre and key CLASSLA corpora available to researchers.
In the hands-on section, participants worked with CLASSLA-web corpora via the CLARIN.SI NoSketch Engine tool and compared corpus-based procedures with AI-driven interfaces. They split into two groups according to language preference: one working with Croatian data and the other with Slovenian data. For the first time in the CLASSLA-Express series, the workshop also hosted several non-South Slavic speakers, whose outside linguistic perspective proved especially valuable. Working together, mixed-language teams recorded their observations and evaluations in prepared evaluation sheets, comparing corpus evidence with LLM-generated outputs across tasks such as extracting phraseological units, generating usage examples, and identifying literal vs. figurative meanings.
The workshop wrapped up with such a dynamic flow of discussion that 19:00 – our scheduled end – arrived almost unnoticed.
With this workshop, we conclude a two-year CLASSLA-Express chapter spanning versions 1.0 and 2.0. Those who have travelled with us so far are warmly invited to stay tuned: CLASSLA-Express 3.0, with a new focus on spoken corpora, is already on the horizon.






Report from the CLASSLA-Express 1.0 Plus “Corpora meets AI” stop in Graz, October 2025
The CLASSLA-Express 1.0 Plus workshop took place on October 10, 2025, at the Department of Slavic Studies at the University of Graz. Building on the previous CLASSLA-Express 1.0 format, this Plus edition introduced a new focus on the intersection of corpus linguistics and artificial intelligence. Led by Ivana Filipović Petrović, the main part of the workshop combined hands-on training in the use of CLASSLA-web corpora for South Slavic languages with discussions on AI-based approaches and the integration of large language models in linguistic research.
According to the registration data, about 85% of participants had no prior experience with corpus tools, which made the workshop particularly innovative and useful. Through guided exercises, participants learned to build and refine queries and gained practical insight into the methodological aspects of corpus-based research.
In the second part, participants compared the output of large language models with authentic corpus data. This comparison revealed both the potential usefulness of AI-generated results and the clear need to verify authenticity and reliability through corpora.
The program also featured presentations by Jelena Stojković, who presented recent corpus-based studies conducted at the Department of Slavic Studies in Graz, and Marko Simonović, who discussed ongoing work and future prospects for regional and minority language corpora. These parts of the program attracted particular interest from the local academic community, especially those involved in corpus building and Slavic linguistics.
In sum, the workshop offered a valuable opportunity to connect corpus methods with emerging AI technologies, promoting both critical reflection and practical collaboration among researchers at different stages of experience.
It was an excellent warm-up for the final CLASSLA-Express stop this year, coming up in November at Bled, Slovenia.


Report from the CLASSLA-Express 2.0 stop in Zagreb, June 2025
First Stop: Zagreb!
The very first workshop in the renewed CLASSLA-Express format took place on June 11 at the Faculty of Humanities and Social Sciences in Zagreb, as part of the Croatian Association of Applied Linguistics (HDPL) pre-conference program. The room was packed (literally – not a seat left!), and the energy was enthusiastic from start to finish.
The session opened with three short talks. Nikola Ljubešić presented recent advances in web corpora and their enrichment with language models, followed by Slobodan Beliga, who gave a concise overview of large language models and generative AI. Ivana Filipović Petrović then offered a glimpse into AI-based tools in phraseological research, focusing on current challenges and opportunities.
At the beginning of the hands-on section, Jelena Parizoska welcomed participants with a brief orientation into the corpus-based approach, building on the foundation set in last year’s series of seven CLASSLA-Express workshops across the region. This introduction helped set the stage for the practical tasks that followed.
Participants explored how corpora and large language models can be used to identify and analyze phraseological constructions. The session sparked lively discussions and offered valuable methodological insights and clear directions for further research.
Feedback from participants was overwhelmingly positive, confirming both the relevance and timeliness of this blended format.
We’re only warming up: the CLASSLA-Express will be back this fall. Stay tuned!




September 2024: Round Table on the Usage of Large Language Models in Corpus-Linguistic Research
On September 18th, the CLASSLA Knowledge Centre hosted a round table on the use of Large Language Models (LLMs) in corpus-linguistic research. This event was part of the pre-conference program for the Language Technologies and Digital Humanities Conference (JTDH 2024). During the engaging discussion, corpus linguists, computational linguists, and other experts in language technologies shared their perspectives on the benefits and challenges of incorporating LLMs into corpus-linguistic research.
The key takeaways from the discussion are as follows:
- LLMs are a disruptive technology with significant impact on all fields working with language, which includes corpus linguistics.
- The rise of LLMs will not render corpora obsolete. There is no need to worry that LLMs will completely replace traditional approaches, they will rather accompany them.
- Our responsibility is to define a methodologically sound way of combining the traditional and LLM approaches, including where they fit within our workflows and how to evaluate their effectiveness.
- Corpus-linguistic studies require real examples, source of the information, controlled datasets, and reproducibility – criteria that LLMs, as black-box models, currently cannot meet.
- On the question of machine-generated content, as long as it is perceived by humans, thereby impacting the language, it is relevant for corpus linguistics, and therefore should be included into corpora.
- LLMs still struggle with basic counting tasks, so frequency-related analyses should remain within the realm of traditional corpus linguistics and statistical analysis and modeling.
- LLMs can be a highly valuable tool for enriching text corpora by providing additional metadata, such as information on genre, sense, idiomacity, or other features of the words and texts in the corpus. The most significant breakthrough LLMs may bring lies in the automatic annotation based on multi-layer and semantic features – an area that was previously challenging to automate.
- Panelists encouraged researchers to experiment with LLMs for automating text annotations and streamlining parts of their research. However, they emphasized the importance of validating the LLMs’ performance on manually-annotated samples for each specific task.

We would like to extend our gratitude to the panelists: Špela Arhar Holdt, Ivana Filipović Petrović, Simon Krek, Taja Kuzman, Jelena Parizoska, Tanja Samardžić, and Luka Terčon. Special thanks also to Nikola Ljubešić, the moderator and event organizer, as well as to the audience for their valuable contributions to the discussion.
April to November 2024: CLASSLA-Express – Workshops on using CLARIN.SI corpora in language research
From April to November 2024, a series of workshops CLASSLA-Express took place in 5 countries: Croatia (Zagreb and Rijeka), Serbia (Belgrade and Kragujevac), North Macedonia (Skopje), Bulgaria (Sofia) and Slovenia (Ljubljana). The workshops showed participants how to use the CLASSLA web corpora in language research. They comprised hands-on exercises showing how to create queries in corpora for Bulgarian, Croatian, Macedonian, Serbian and Slovene. More details on the CLASSLA-Express workshops are available here.
Report from the first two stops of CLASSLA-Express: Zagreb and Rijeka
The CLASSLA-Express is in full swing, with two workshops already underway. The first was held on April 19 at the Faculty of Humanities and Social Sciences in Zagreb, with 22 participants. Following that, the second workshop was held at the Faculty of Humanities and Social Sciences in Rijeka, with 16 participants in attendance.
Each workshop was divided into two parts: the first one focused on theory and the second on practical applications. Both workshop convenors gave introductory lectures during the theoretical part. Ivana Filipović Petrović introduced the Slovenian national consortium CLARIN.SI and presented the CLASSLA corpora developed at the CLASSLA Knowledge Centre. Jelena Parizoska provided an overview of the application of computer corpora in linguistic research.
The practical part of the workshops was dedicated to introducing participants to basic and advanced searches in the NoSketch Engine tool, which hosts freely accessible CLASSLA-web corpora. Participants actively engaged in the exercises, posing questions related to their specific linguistic interests. They were particularly interested in formulating CQL queries with the convenors on-site and doing exercises where they had to find results themselves. Many highly up-to-date questions, such as how to use the power of large language models in linguistic research, were raised during the discussion. An overall conclusion was that we still need corpora for trustworthy examples and distributions of human usage of language, but that large language models can be used for enrichment or filtering of the corpus evidence.
Continuing onward, the CLASSLA-Express team is very excited about the upcoming stops.




Report from the CLASSLA-Express stop in Belgrade
The CLASSLA-Express continues its route, with its third workshop successfully completed on May 29 in Belgrade, Serbia. This event was part of the Leksikografski susreti conference held at the Faculty of Philology, University of Belgrade. The workshop, convened by Ivana Filipović Petrović, attracted 21 participants, reflecting a strong interest in complex CQL exercises and corpus research in general.
Similar to the past two workshops, the session was divided into theory and practical application. Ivana Filipović Petrović introduced the Slovenian national consortium CLARIN.SI and CLASSLA Knowledge Centre during the theoretical part. The practical part focused on familiarizing participants with both basic and advanced searches using the CLARIN.SI NoSketch Engine tool, which hosts the freely accessible CLASSLA web corpora. Participants were particularly engaged in the hands-on exercises, especially those involving CQL queries, and showed a keen interest in finding results independently.
The last section of the workshop was dedicated to addressing individual queries from participants related to their corpus research, which proved to be beneficial to everyone involved. Additionally, we are happy to announce that following a proposal by one of the workshop attendees, a new CLASSLA-Express workshop is scheduled to take place in Kragujevac, Serbia in the fall.


Report from the CLASSLA-Express stop in Skopje
The fourth CLASSLA-Express workshop was held on June 4 in Skopje, at Blaže Koneski Faculty of Philology. The event was opened by Dean Vladimir Martinovski. The workshop was convened by Jelena Parizoska, with 14 participants in attendance – faculty members of Ss. Cyril and Methodius University in Skopje and University St. Kliment Ohridski – Bitola, with a background in modern Slavic, Germanic and Romance languages, Language For Specific Purposes, as well as translation and interpreting. Given that CLASSLA-web.mk is the first general corpus of Macedonian, the workshop exclusively focused on that language.
The introductory part contained basic information about CLASSLA web corpora, after which the convenor provided details on using corpus data in research of Macedonian. This was followed by tasks which allowed participants to query the CLASSLA-web.mk corpus. The exercises included queries which can be used in research of any South Slavic language, as well as those specifically pertaining to Macedonian, such as the definite and indefinite forms of nouns.
Throughout the workshop, the participants were encouraged to make suggestions on querying the corpus based on their own research interests. One of those was figurative language, which resulted in jointly creating queries involving idiomatic expressions containing a specific word, and searching for variations of proverbs. Hands-on tasks proved to be particularly useful to participants, as they may be used in both research and teaching.


Report from the CLASSLA-Express stop in Sofia
The fifth CLASSLA-Express workshop was held on June 26 in Sofia. The focus of this stop was on the usage of CLASSLA web corpora for Bulgarian. The workshop, convened by Jelena Parizoska and Petya Osenova, attracted 25 registered participants from various backgrounds – students of Bulgarian language and Slavic Philology, university lecturers of Bulgarian as a first and foreign language, also of Slavic Grammar, scientists from various institutes of the Bulgarian Academy of Sciences, such as the Institute of Balkan Studies and the Division of Bulgaria Encyclopedia.
First, the participants were introduced to the mission of CLARIN.SI, CLaDA-BG and the CLASSLA Knowledge Centre. Then, they were instructed how to use large Bulgarian corpora for targeted searches. The main portion of time was organized as hands-on sessions where the participants could perform their own searches and ask related questions.
The lessons learned are as follows: a) such trainings proved to be very much appreciated by all types of users – advanced ones as well as beginners; b) the preliminary preparation of the handouts and instructor’s copies is crucial for the smooth workflow; c) the scenario-oriented searches are a successful technique during trainings.



Report from the CLASSLA-Express stop in Ljubljana
On September 18, the CLASSLA-Express train made a stop in Ljubljana, marking the sixth workshop in the series. This workshop was part of the pre-conference program of the Slovenian Language Technologies and Digital Humanities Conference (JTDH 2024).
The workshop was convened by Jelena Parizoska and Ivana Filipović Petrović, with 15 participants in attendance. The presence of the creators of CLASSLA-web corpora – Nikola Ljubešić and Taja Kuzman – proved invaluable in discussions with participants, given that a number of questions were related to linguistic annotation and metadata enrichment, such as genre categories and MULTEXT-East part-of-speech tagsets. The questions posed to the convenors during discussions pertained to participants’ specific interests, e.g., searching for variations of idiomatic expressions in corpora and applying corpus data in lexicography.
The workshop was followed by another JTDH 2024 pre-conference event – a round table on the use of Large Language Models (LLMs) in corpus linguistic research – which was convened by Nikola Ljubešić, with Ivana Filipović Petrović, Jelena Parizoska and Taja Kuzman participating as panellists.


Report from the CLASSLA-Express stop in Kragujevac
On November 20, 2024, the CLASSLA-Express made its final stop for the year in Kragujevac, Serbia. The workshop, convened by Ivana Filipović Petrović, was attended by 11 participants, predominantly foreign language teachers from the Faculty of Philology and Arts. The workshop fostered lively discussions, focusing on participants’ specific areas of interest.
As with previous workshops, the session included both a theoretical introduction and a hands-on segment. The theoretical portion provided an overview of the CLASSLA Knowledge Centre and the tools available for South Slavic languages. The practical segment focused on querying the CLASSLA-web corpora on the CLARIN.SI NoSketch Engine concordancer, with participants tackling both basic and advanced queries.
As we wrap up this year’s successful CLASSLA-Express journey, we invite everyone interested in corpus linguistics and LLMs to stay tuned for more stops and exciting plans next year.


November 2021: Workshop on regional markedness in text
On 6 and 7 November 2021, an online workshop dedicated to regional markedness in text took place, organised by the ReLDI centre, University of Zurich, and CLASSLA.
The program of the two-day event included the keynote talk on Computational dialectology by Yves Scherrer from the University of Helsinki, Darja Fišer’s presentation of the student research at the JTDH Language Technologies and Digital Humanities Conference, and two interactive workshops: Interactive workshop on regional variation in text, led by Sara Košutar, Larissa Schmidt, and Leyla Feiner, and Regional variation in gender marking: a hands-on tutorial on extracting data from corpora, led by Mirjana Starović and Tanja Samardžić.
The materials for the workshop on regional variation in gender marking are available here. They provide a gentle introduction to the process of analysing corpora, containing information on:
- which South Slavic corpora are available on the CLARIN.SI repository, and how to find comparable corpora
- how to explore corpora through the noSketchEngine and KonText concordancers
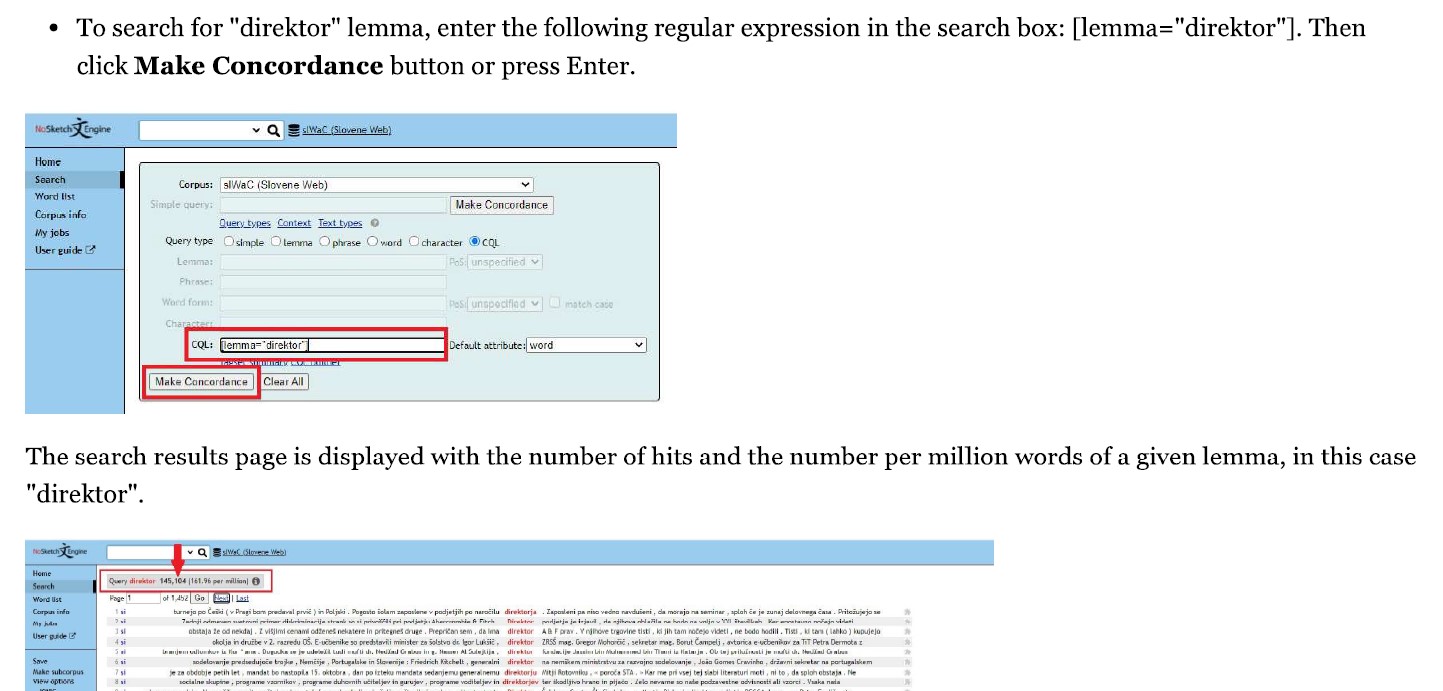
- how to query the corpora using the CQL (Corpus Query Language) syntax
- how to analyse gender marking in each South Slavic corpus by analysing the number of occurrences of feminine and masculine nouns describing occupations (e. g. the feminine and masculine nouns for the word “director”)
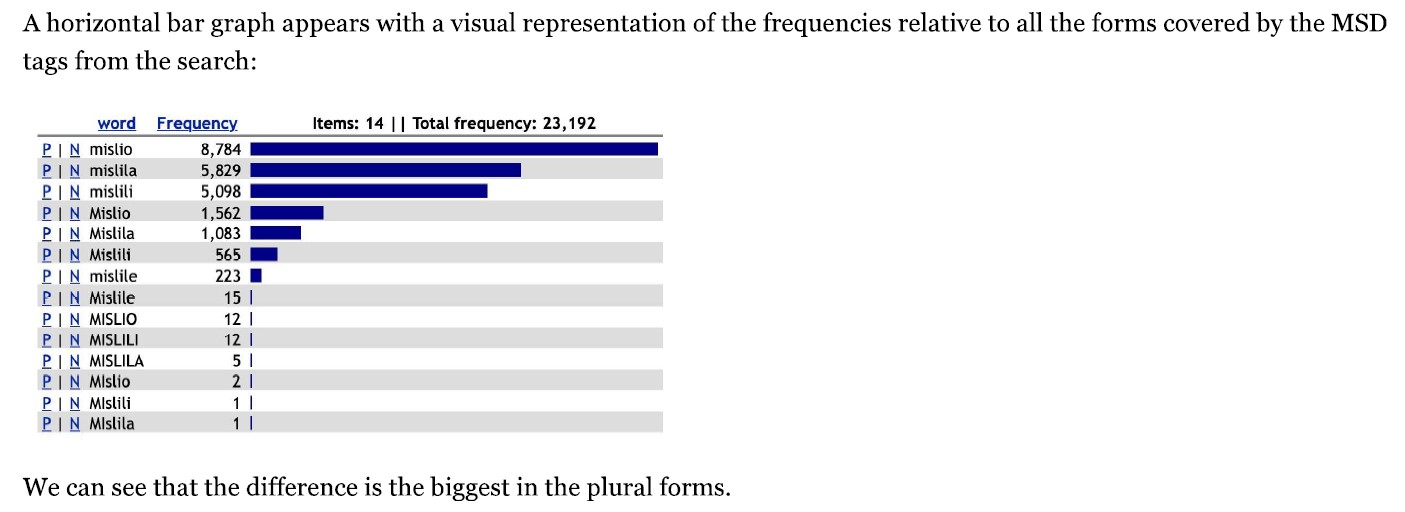
- how to use the morphosyntactic descriptions (MSDs) to analyse the distribution of verbs with feminine and masculine suffixes (e.g. “mislila” vs. “mislil” for “she/he thought”)
- and finally, how the results can be interpreted to analyse gender bias in society.
Some excerpts of the document are presented below:
May 2020: First CLASSLA K Centre workshop
The first CLASSLA K Centre workshop was supposed to be held from May 6 to May 8 2020 in Ljubljana, but due to the COVID-19 crisis, the face2face workshop had to be postponed. However, in the process of selecting participants a very nice crowd came together, so we decided to host an online Zoom session on May 6, the day we should have all met in Ljubljana.
The session took two hours, and in the first hour all the participants briefly presented themselves. In the second hour of the session, a short discussion on the future steps for the workshop and the knowledge centre were discussed, kick-started with the results on the survey taken by the participants before the online session. Also, the ReLDI centre for linguistic data was presented as well as the current CLARIN ERIC funding opportunities.
This discussion revealed the following priorities: (1) connecting web services with concordancers is a very sought feature, so that researchers could easily process and publish their textual raw data, (2) the Knowledge centre might need a form for reporting use cases on its resources (a draft of such a form has been made available here), and (3) the participants are very interested in holding group discussions on specific topics, which will be organised in the weeks to come.
The whole online session seemed to be a very pleasant experience for the 42 participants and we have the Zoom photos of the participants below to prove that!
We are still looking forward to the face2face workshop which we hope will take place during the next year.