An introduction to the comparable CLASSLA web corpora for South Slavic languages, providing details on the corpora sizes and interesting insights based on genre distributions.
Nikola Ljubešić and Taja Kuzman · December 5, 2023 · 3-minutes read
The CLASSLA Knowledge centre for South Slavic languages has released comparable web corpora for all official South Slavic languages, namely Slovenian, Croatian, Bosnian, Montenegrin, Serbian, Macedonian and Bulgarian, all the corpora summing up to almost 11 billion words! The corpora are freely available on the CLARIN.SI NoSketch Engine concordancer (see our recent tutorial on how to easily query the CLASSLA web corpora and perform statistical analyses via the concordancer).
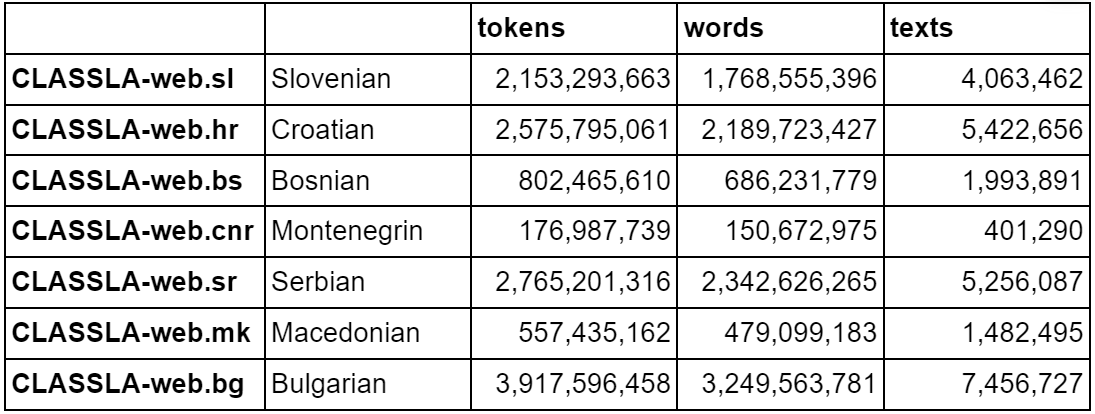
The sizes of each of the corpora in terms of number of tokens, words and documents, are given in the table below.
This collection of corpora is very innovative, due to the following reasons:
- This is, to the best of our knowledge, the first collection of comparable web corpora covering a whole language group.
- The collection includes the first general, linguistically annotated corpora for two out of seven languages, namely Montenegrin and Macedonian.
- The comparability of the corpora is ensured by performing data collection and filtering in the same time period with the same technologies. Furthermore, the corpora underwent a uniform linguistic processing via the CLASSLA-Stanza toolkit, which you can now try out also through the CLASSLA annotator web interface.
- Each of the documents in each of the corpora is annotated with the X-GENRE multilingual genre classifier. The normalized distribution of genre labels inside the CLASSLA web corpora are presented in the following figure.
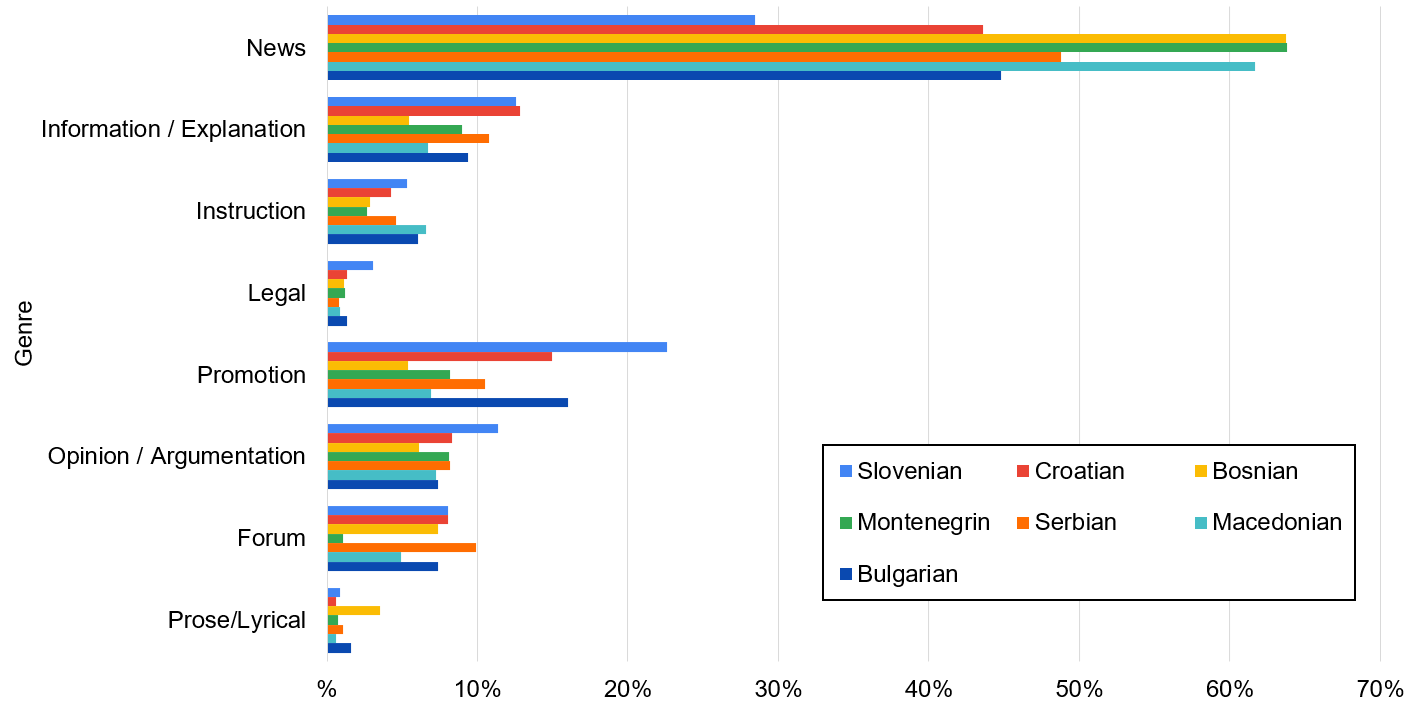
The comparison of genre distributions across CLASSLA web corpora shows limitations of the comparability of web crawls performed even in neighboring linguistically related countries. Thanks to the automatically annotated genre information, the differences between the corpora can be circumvented by controlling for the genre distribution. Interested in the reasons for such strong differences between the genre distributions, one can already visually identify that the news genre on one side, and the promotion genre on the other are the main driving forces of difference between genres across these seven languages, and on top of that, very negatively correlated between each other. Hypothesizing that the amount of promotion material on a national web corresponds to the amount of economic activity, we preliminarily investigated how the GDP PPP per capita across the seven countries correlates with the promotion and the news genre distributions. By calculating the Pearson correlation, we obtain a very high positive correlation between GDP PPP per capita and the promotion genre (r=.938, N=7, p=.002), as well as a very high negative correlation between GDP PPP per capita and the news genre (r=-.9, N=7, p=.006). This is only a very small example of the interesting insights that one can obtain from having genre information on every of the 26 million documents. We are very excited to see all of the interesting research that will be performed on the CLASSLA web corpora!
We will be very glad to obtain feedback on our corpora and annotation technology. As usual, please write to us on helpdesk.classla@clarin.si!
These corpora would not have been released without great collaboration inside the CLASSLA Knowledge centre for South Slavic languages, which includes the Slovenian consortium CLARIN.SI, the Institute of Croatian Language, and the Bulgarian consortium CLADA-BG. Furthermore, very crucial were the longstanding collaboration with the ReLDI centre on a series of South Slavic languages, and Biljana Stojanovska and Katerina Zdravkova on Macedonian. On this occasion, we want to thank everyone for the collaboration, and invite others to join our common efforts!