A tutorial on how to use a CLARIN.SI tool for easy querying and statistical analysis of text collections, especially appropriate for linguists, language teachers, digital humanists, corpus linguists and others. We show you how you can query new massive web text collections for Croatian, Slovenian and Serbian and find collocations, word statistics, context of non-standard words and more.
Taja Kuzman and Nikola Ljubešić · June 22, 2023 · 10-minutes read
CLASSLA-web are new massive web corpora for Slovenian (CLASSLA-web.sl), Croatian (CLASSLA-web.hr) and Serbian (CLASSLA-web.sr). These are pilot corpora for the web corpora of all South Slavic languages that will be published later this year by the CLASSLA Knowledge Centre for South Slavic languages. In this blog post, we will show you how you can query them on the CLARIN.SI concordancers to explore word usages, collocations, good dictionary examples, differences in usage in different genres and more.
Concordancers are computer programs that enable effortless searching and statistical treatment of data in big text collections (= corpora) also for those that are less tech-savvy. The Slovenian research infrastructure CLARIN.SI provides three open concordancers, and you can access the CLASSLA web corpora on all three of them (read more here on how they differ). The examples in this post are from the CLARIN.SI noSketchEngine concordancer, an open-source version of the commercial Sketch Engine, which was developed by Lexical Computing. The corpora are available for querying here: CLASSLA-web.sl, CLASSLA-web.hr and CLASSLA-web.sr. Feel free to open them and try to reproduce the steps in the blog post, while you are reading it, and then experiment some more on your own. We are very interested in your experience with the corpora. Let us know if you noticed anything that you liked or disliked via helpdesk.classla@clarin.si.
Introducing the CLASSLA web corpora
As part of the MaCoCu project, we collected monolingual and parallel web corpora for more than 10 European under-resourced languages and made them freely available (you can download them at https://macocu.eu/). They can be used for training machine translation systems, language models and other language technologies. To make the datasets more usable for linguists and corpus linguists, the CLASSLA team linguistically annotated the monolingual datasets for Slovenian, Serbian and Croatian with the state-of-the-art pipeline for linguistic annotation CLASSLA Stanza. Additionally, we enriched them with metadata on genre with the multilingual genre classifier X-GENRE. Finally, we made them freely available at the CLARIN.SI concordancers. In this blog post, we will show you what kind of insights can linguists and digital humanists obtain from the CLASSLA web corpora with just a few clicks.
But first, some information on the corpora
The CLASSLA web corpora come from the MaCoCu-sl, MaCoCu-hr and MaCoCu-sr monolingual corpora. They were collected by crawling primarily the national top-level internet domains, that is, “.si” for Slovenian, “.hr” for Croatian and “.rs” and “.срб” for Serbian, but also crawling generic (“.com”, “.net” etc.) domains well connected to websites on respective top-level domains. You can find more information on the corpora collection and curation at https://macocu.eu/ and at the dataset entries on the CLARIN.SI repository (MaCoCu-sl, MaCoCu-hr and MaCoCu-sr).
Each CLASSLA web corpus comprises around 2 billion words and 6 to 8 million texts. The Slovenian and Croatian CLASSLA web corpora are roughly two times bigger than the previous web corpora for these two languages, the slWaC and the hrWaC, while the Serbian corpus is even 5 times bigger than the previous web corpus, the srWaC!
In addition to being much bigger, the CLASSLA web corpora are much more recent, which means that they include terms that have been only recently introduced, such as the “COVID-19”, “self-isolation” and so on. They include texts published up to 2021 (CLASSLA-web.sl) or even 2022 (CLASSLA-web.hr and CLASSLA-web.sr). They also provide rich metadata, including information on:
- the web domain and URL of the text
- the genre of the text
- language identification information
- script (Latin or Cyrillic, for Serbian only)
Obtaining context for non-standard words
The web corpora do not include only texts that were written by professional writers in a formal context. They aim to encompass all the texts written on the web. Thereby, they also include texts from forums and personal blogs. Thus, they can provide valuable insight into dialectal and non-standard use of language. You can find information on the usage of words that are not included in a general dictionary.
For instance, the Slovenian word “metek” (“bullet”) is shunned by the Slovenian linguists and copy-editors, because it is thought to be a loan word from Croatian and Serbian. It is not included in the Slovenian general dictionaries and copy-editors will replace it with Slovenian equivalents “izstrelek” or “krogla”. However, native Slovenian speakers still feel that this word is a legitimate Slovenian word and we can explore how they use the word on the web in CLASSLA-web.sl.
We can find the sentences that contain the word (= concordances) by clicking on the button CONCORDANCE on the dashboard or on the icon for the concordance in the menu bar on the left.
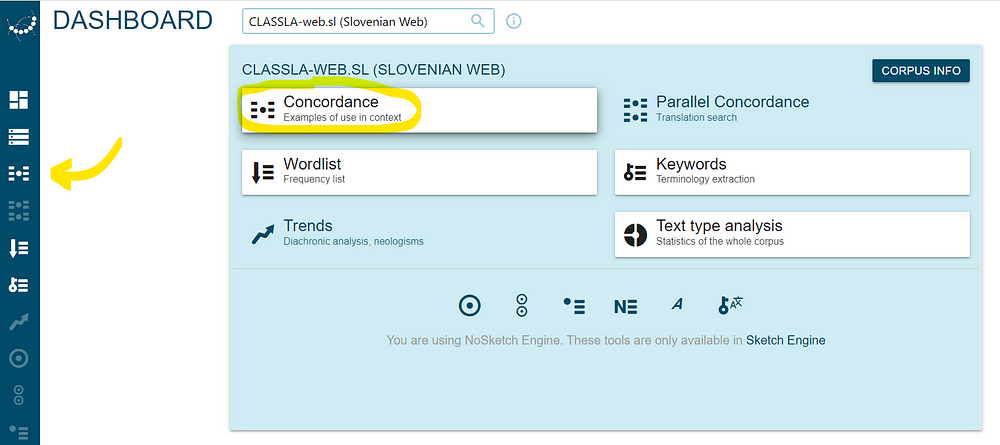
We simply input the word and press SEARCH.
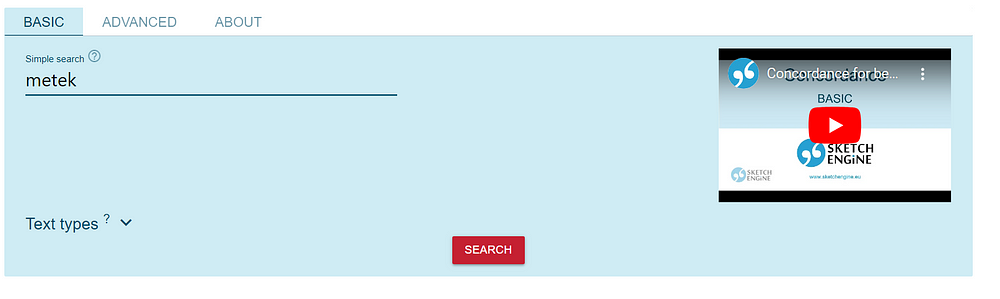
We obtain a list of concordances with the word “metek” — there are around 2000 sentences in the Slovenian web corpus with this word.
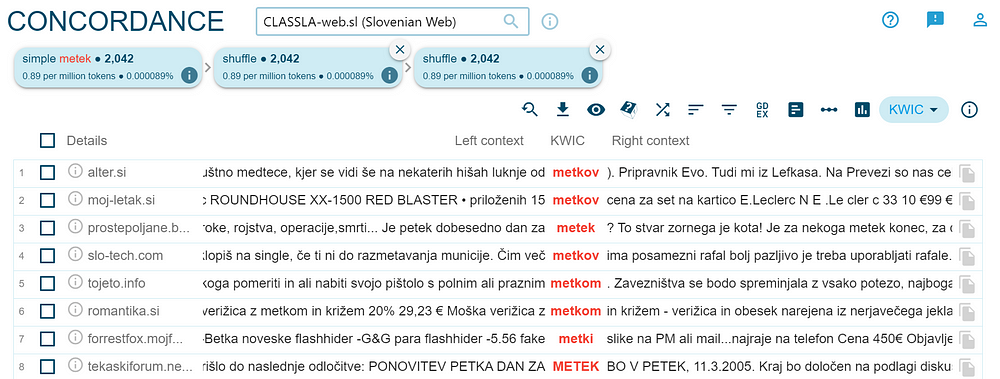
We can inspect in which text types (genres) the word occurs the most by clicking on the icon for Frequency.

Click on the button TEXT TYPES to get more information on the occurrence of the word in specific genres, presented below:
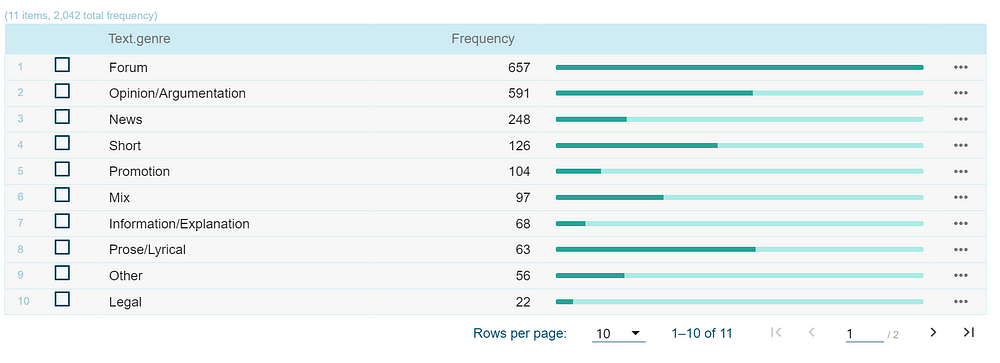
We can see that the word “metek” is most frequently used in Forums and Opinionated texts where people express themselves freely. However, surprisingly, we can also find this word in News and even in Legal texts. By clicking on the three dots on the right, you can inspect the concordances inside a specific genre.
Searching for collocations
As the CLASSLA web corpora were collected in 2021 or 2022, they also provide information on recent words, such as words, connected with the COVID-19 pandemic. We can obtain information on how these words are used in context and with which words they often co-occur.
For instance, to see which words often co-occur with the Croatian word “karantena” (“quarantine”), we first search for the word in the Concordance window inside the CLASSLA-web.hr corpus, as we did with “metek”. Once the window with the concordances opens, choose the button for Collocations:
You can specify whether you are searching for words on the left or the right side of your word and how far from the word they appear. You can also choose whether you want the list to show words (word forms as they appear in the text), lemmas (base, dictionary forms of words), part-of-speech tags (to investigate whether this word is surrounded by verbs or nouns more often), and so on.
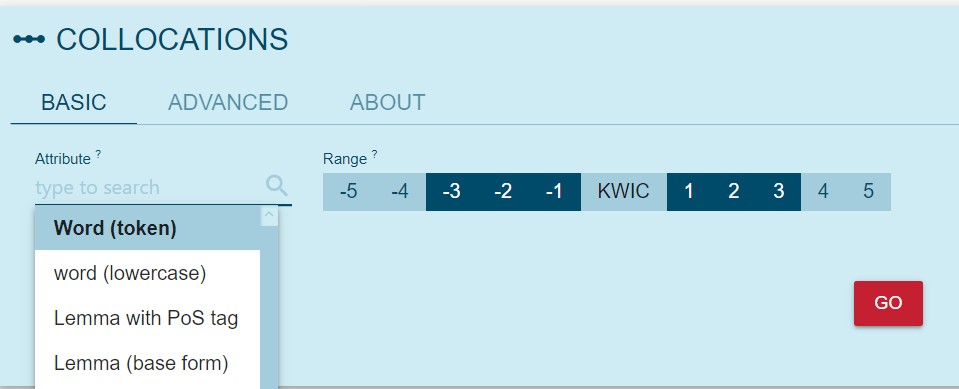
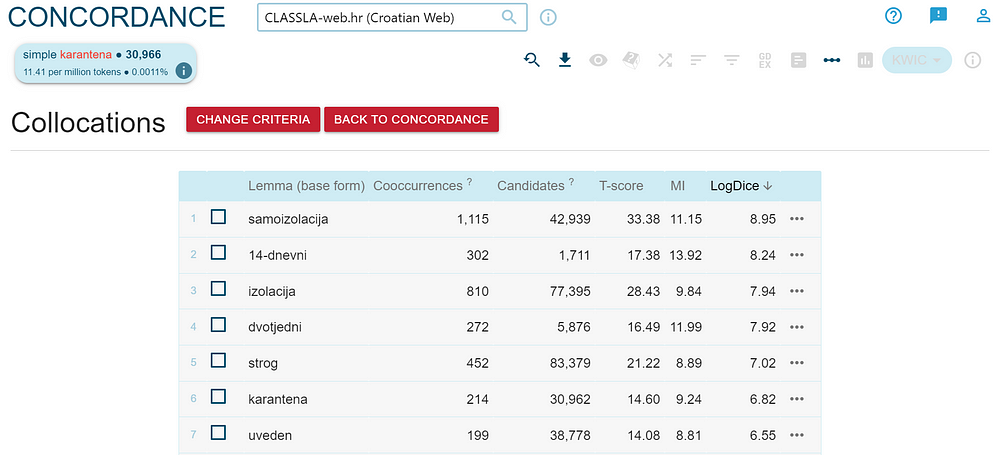
Below, we see the results — we can see that the Croatian word “karantena” (“quarantine”) co-occurs often with the word “samoizolacija” (“self-isolation”), with the adjectives describing the length of the quarantine (14-days, 2-week) and other related words.
Now, what if we want to find only verbs that occur with the word “quarantine”? We can do that by using the advanced search for the concordance. As shown in the example below, we specify that we are searching for two words — the first needs to be a verb ([pos=”VERB”]), and the second is the word “karantena” ([lemma=”karantena”]) in any form. If you are not familiar with this format, the CQL BUILDER can lead you through the process of creating such query.
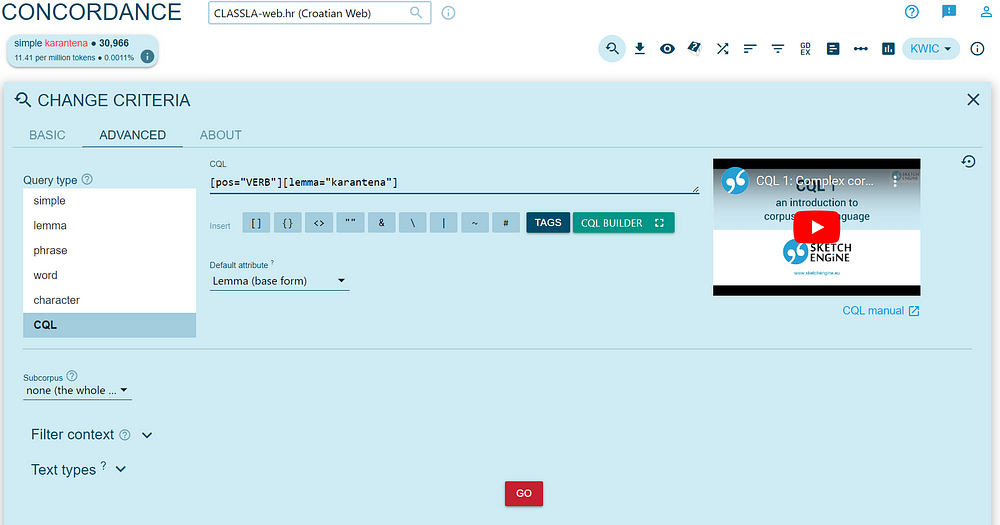
A list of concordances with this phrase appears. To get a list of the most frequent combinations of verbs and the word “karantena”, click on the button for Frequency and choose the option “LEMMAS” for KWIC (Key Word in Context).
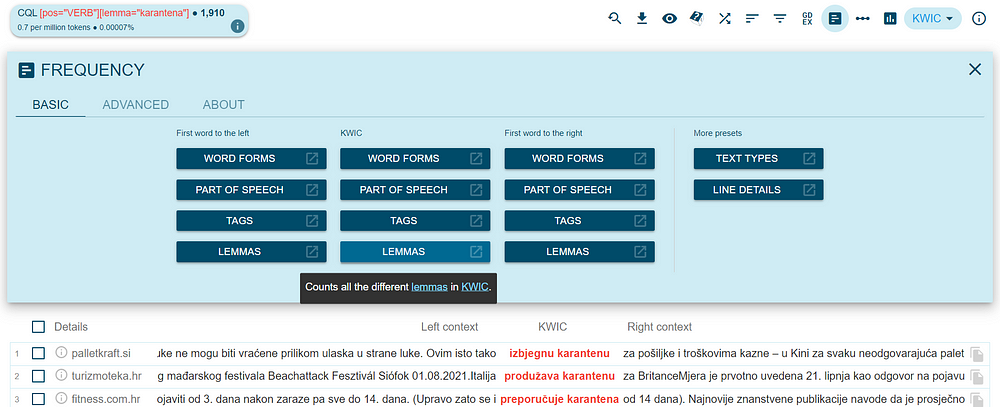
A list with hits with the words in their base, dictionary form appears. By clicking on the three dots on the left, you can inspect examples for a specific phrase. We can see that the most frequent verbs that precede the word “karantena” (“quarantine”) are “uvesti” (“impose”), “proglasiti” (“announce”), “uvoditi” (“introduce”), “proći” (“get through”), and “izbjeći” (“avoid”).
Obtaining the most informative examples
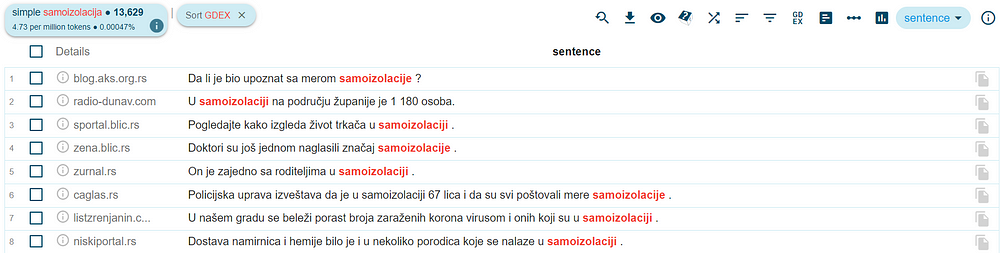
The NoSketch Engine concordancer also provides an option to automatically identify sentences which are easy to understand and especially illustrative for language learners. If you are curious on how you should use the Serbian word “samoizolacija” (“self-isolation”), you can search for the concordances with this word in the CLASSLA-web.sr corpus and then click on the icon Good Dictionary Examples (GDEX):
The tool provides nice examples of how the word is used in sentences in combination with common collocations and in common word forms:
Genre in the CLASSLA web corpora
Genre of the texts was automatically identified with the multilingual genre classifier X-GENRE. Genre is a phenomenon, observed on the text level, so if a web text is very short (consists of 75 words or less), we deemed it to be inappropriate for reliable genre prediction, and was annotated as “Short” instead. If the text has characteristics of multiple genres, it was annotated as “Mix”. Genre metadata allow us to easily perform linguistic and sociolinguistic analysis on how certain words or phrases are used in different situational contexts.
For instance, let’s look at how the Croatian word “pas” (“dog”) is used in various text types in the Croatian CLASSLA-web.hr corpus. When searching for the concordances, specify the genre of your choice in the option Text types, as shown below:
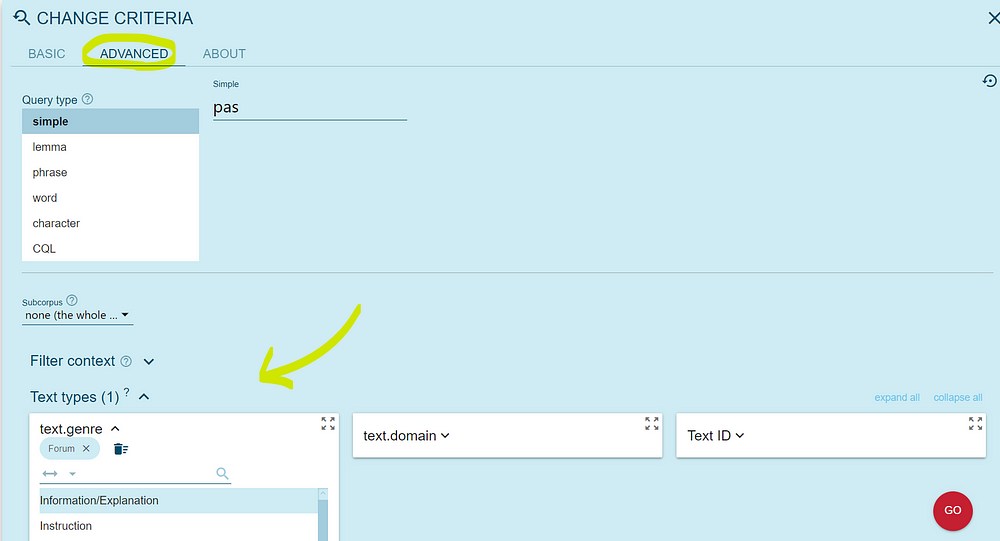
Once the list with concordances appears, click on the Collocations button, as we did with the word “karantena”, and inspect lemmas that occur directly to the right and left of the word “pas”:
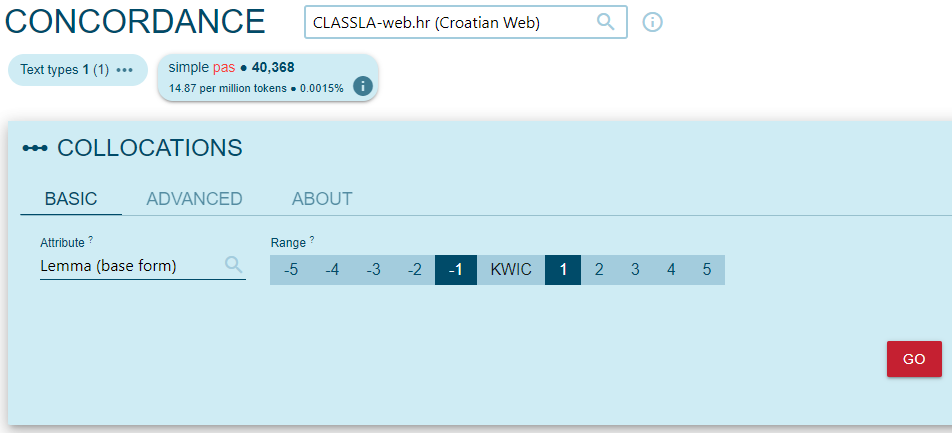
This is how we obtain collocations for the word, used in a specific genre. For instance, the most frequent collocations in texts from Forums are “pas mater” (“dog (does sth. to) mother”) — which is a part of a Croatian swear word (click on the three dots on the left to find out which) — , “pas lajati” (“dog bark”) and “dupli pas” (“one-two” — a sports term).
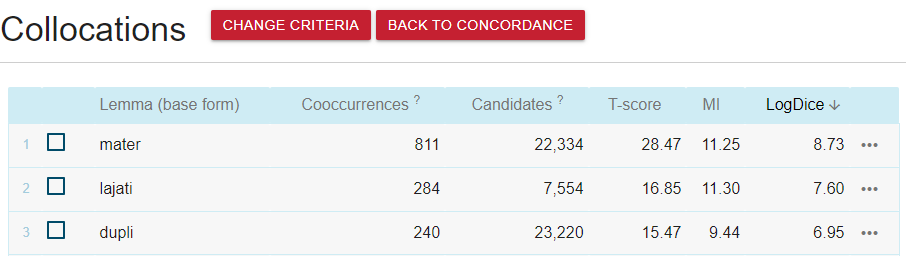
If we repeat the steps and choose different genres, we can see how the most frequent collocations with this word change depending on the text type. Here are some instances from the most frequent collocations:
- Legal: “neupisan pas” (“unregistered dog”), “mikročipiranje pasa” (“microchipping a dog”)
- Promotion: “šišanje pasa” (“dog grooming”), “izbirljiv pas” (“picky-eater”)
- News: “potražni pas” (“search dog”), “pas lutalica” (“stray dog”)
- Opinion/Argumentation: “bijesan pas” (“mad/rabid dog”), “susjedov pas” (“neighbour’s dog”)
- Instruction: “vaš pas” (“your dog”), “udomiti psa” (“adopt a dog”)
- Prose/Poetry: “čovjekoliki pas” (“human-like dog”), “pas tragač” (“bloodhound”)
- Information/Explanation: “lovački pas” (“hunting dog”), “pastirski pas” (“sheep dog”)
Leveraging other metadata
The Serbian CLASSLA-web.sr corpus also provides information whether the text was originally written in Cyrillic or Latin.
Let’s search for the phrase “vakcinacija” (“vaccination”) in the Serbian corpus. Then click on the Frequency button and choose TEXT TYPES.
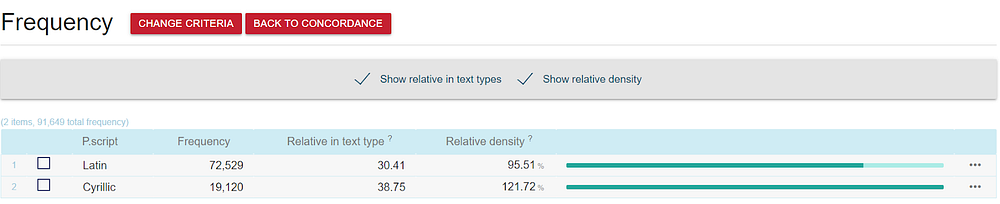
The Relative Density metric tells us the relative frequency of the phrase in a text type — if it is above 100%, that means that the phrase is more frequent in this text type than in the entire corpus and that it is typical for this text type. Based on this metric, we can see that vaccination is more frequently discussed in Cyrillic than in Latin texts.
Let us then search for another term, “antivakser” (“anti-vaxxer”), and inspect the text type distribution again.

It seems that vaccination is more frequently mentioned in the Cyrillic script, while people opposing vaccination are being discussed more in the Latin script.
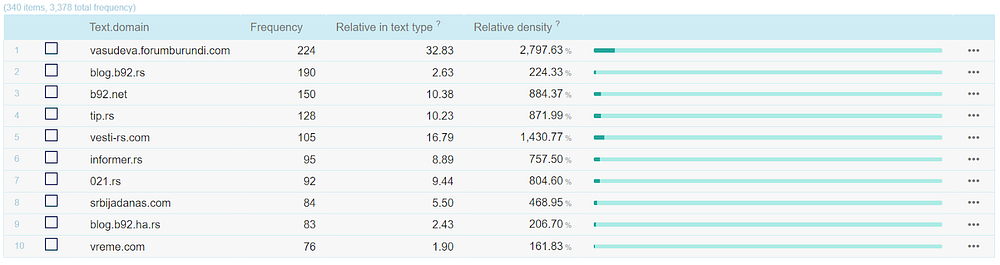
On the same page, we can also obtain information on which web sites the word occurs most frequently. By clicking on the three dots on the left, we can inspect instances that come from that specific web site. From the statistics for the word “antivakser” (“anti-vaxxer”), we can see that this topic is the most discussed in forums and blogs.
Conclusion
To sum up, in this blog, we have shown:
- how you can search for any word or phrase in massive web corpora of Slovenian, Serbian and Croatian. Since these text collections comprise also texts that were not written by professional writers, we can also find slang and dialectal words, as well as other non-standard language features that might not be present in dictionaries and standard text collections;
- how you can search for collocations of words using the Collocations feature and even filter them by genre;
- how you can search for more specific collocations, such as a phrase that consists of a verb that precedes a certain noun, by using the Advanced search option and the Frequency feature;
- how you can analyse the frequency of a word or a phrase in different genres, web sites, and — for the Serbian corpus — also for different scripts;
- how you can obtain most informative examples of word usage, which can especially help language learners and teachers.
We hope that this tutorial inspired you to use the CLASSLA web corpora for your work, research or other uses. You can access them for free from these links: CLASSLA-web.sl, CLASSLA-web.hr and CLASSLA-web.sr.
We will be very happy to hear from you — let us know what about the CLASSLA web corpora you like and dislike via helpdesk.classla@clarin.si. If you are interested in South Slavic resources and technologies, we also invite you to join the CLASSLA mailing list and to follow the CLARIN.SI infrastructure on Twitter.